
Publications
You can also find my articles on my Google Scholar Profile.Show selected / Show all by date / Show all by topic
2025
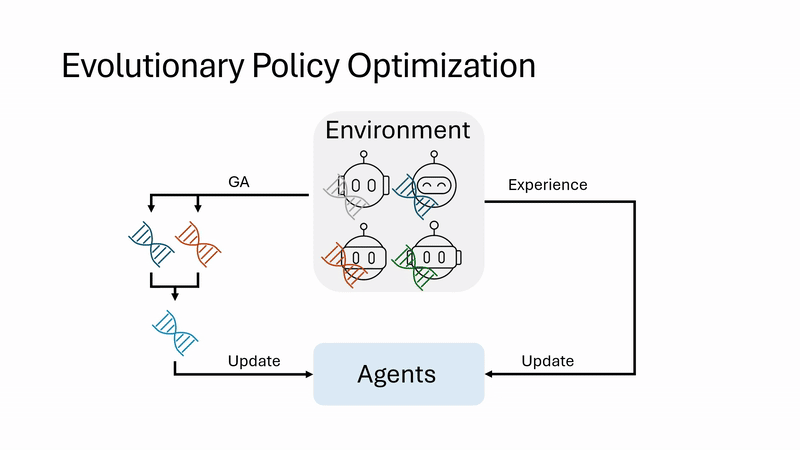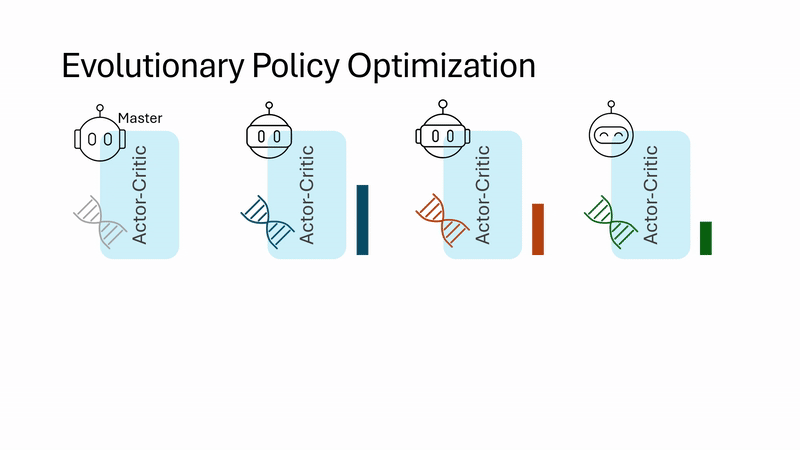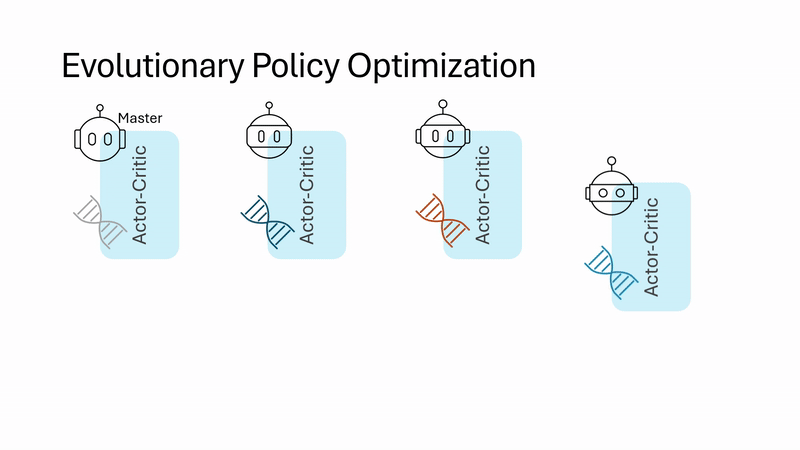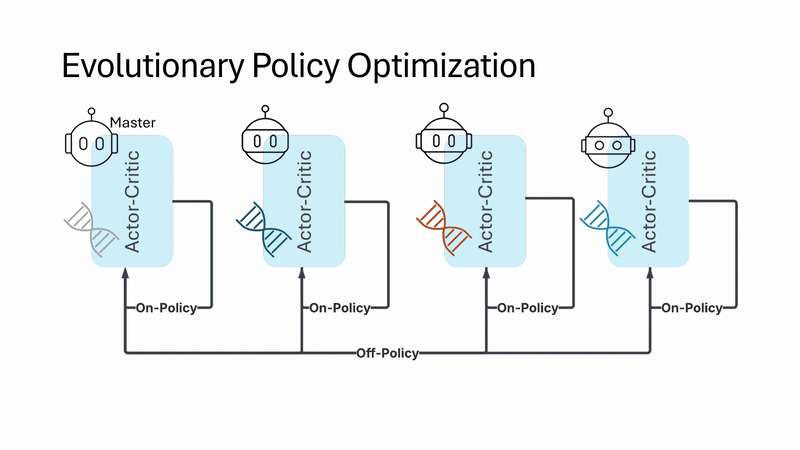 | Evolutionary Policy Optimization Jianren Wang*, Yifan Su*, Abhinav Gupta, Deepak Pathak Preprint [Project Page] [Code] [Abstract] [Bibtex] On-policy reinforcement learning (RL) algorithms are widely used for their strong asymptotic performance and training stability, but they struggle to scale with larger batch sizes, as additional parallel environments yield redundant data due to limited policy-induced diversity. In contrast, Evolutionary Algorithms (EAs) scale naturally and encourage exploration via randomized population-based search, but are often sample-inefficient. We propose Evolutionary Policy Optimization (EPO), a hybrid algorithm that combines the scalability and diversity of EAs with the performance and stability of policy gradients. EPO maintains a population of agents conditioned on latent variables, shares actor-critic network parameters for coherence and memory efficiency, and aggregates diverse experiences into a master agent. Across tasks in dexterous manipulation, legged locomotion, and classic control, EPO outperforms state-of-the-art baselines in sample efficiency, asymptotic performance, and scalability.
@article{wang2025evolutionary,
title={Evolutionary Policy Optimization},
author={Wang, Jianren and Su, Yifan and Gupta, Abhinav and Pathak, Deepak},
journal={arXiv preprint arXiv:2503.19037},
year={2025}
}
|
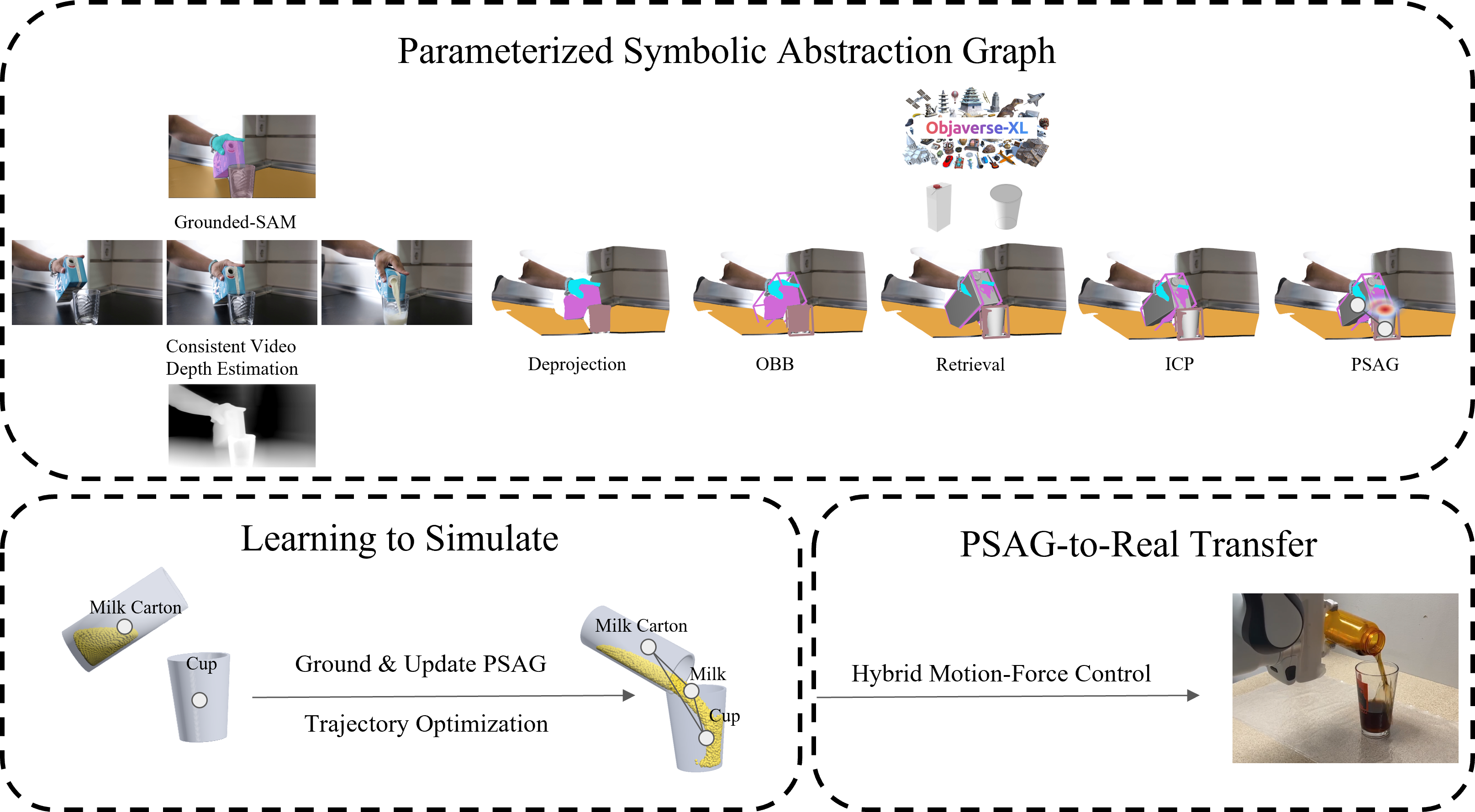 | One-shot Video Imitation via Parameterized Symbolic Abstraction Graphs Jianren Wang, Kangni Liu, Dingkun Guo, Zhou Xian, Christopher Atkeson 2025 IEEE International Conference on Robotics and Automation [Project Page] [Abstract] [Bibtex] Learning to manipulate dynamic and deformable objects from a single demonstration video holds great promise in terms of scalability. Previous approaches have predominantly focused on either replaying object relationships or actor trajectories. The former often struggles to generalize across diverse tasks, while the latter suffers from data inefficiency. Moreover, both methodologies encounter challenges in capturing invisible physical attributes, such as forces. In this paper, we propose to interpret video demonstrations through Parameterized Symbolic Abstraction Graphs (PSAG), where nodes represent objects and edges denote relationships between objects. We further ground geometric constraints through simulation to estimate non-geometric, visually imperceptible attributes. The augmented PSAG is then applied in real robot experiments. Our approach has been validated across a range of tasks, such as Cutting Avocado, Cutting Vegetable, Pouring Liquid, Rolling Dough, and Slicing Pizza. We demonstrate successful generalization to novel objects with distinct visual and physical properties.
@article{wang2025psag,
title={One-shot Video Imitation via Parameterized Symbolic Abstraction Graphs},
author={Wang, Jianren and Liu, Kangni and Guo, Dingkun and Xian, Zhou and Atkeson, Christopher},
journal={ICRA},
year={2025}
}
|
2023
 | Robot Parkour Learning Ziwen Zhuang*, Zipeng Fu*, Jianren Wang, Christopher Atkeson, Soren Schwertfeger, Chelsea Finn, Hang Zhao 2023 Conference on Robot Learning (Best Systems Paper Finalist) [Project Page] [Code] [Abstract] [Bibtex] Parkour is a grand challenge for legged locomotion that requires robots to overcome various obstacles rapidly in complex environments. Existing methods can generate either diverse but blind locomotion skills or vision-based but specialized skills by using reference animal data or complex rewards. However, autonomous parkour requires robots to learn generalizable skills that are both vision-based and diverse to perceive and react to various scenarios. In this work, we propose a system for learning a single end-to-end vision-based parkour policy of diverse parkour skills using a simple reward without any reference motion data. We develop a reinforcement learning method inspired by direct collocation to generate parkour skills, including climbing over high obstacles, leaping over large gaps, crawling beneath low barriers, squeezing through thin slits, and running. We distill these skills into a single vision-based parkour policy and transfer it to a quadrupedal robot using its egocentric depth camera. We demonstrate that our system can empower two different low-cost robots to autonomously select and execute appropriate parkour skills to traverse challenging real-world environments.
@article{zhuang2023parkour,
title={Robot Parkour Learning},
author={Zhuang, Ziwen and Fu, Zipeng and Wang, Jianren and Atkeson, Christopher and Schwertfeger, Soren and Finn, Chelsea and Zhao, Hang},
journal={CoRL},
year={2023}
}
|
 | Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations Jianren Wang*, Sudeep Dasari*, Mohan Kumar, Shubham Tulsiani, Abhinav Gupta 2023 International Conference on Computer Vision (Oral) [Project Page] [Code] [Abstract] [Bibtex] The field of visual representation learning has seen explosive growth in the past years, but its benefits in robotics have been surprisingly limited so far. Prior work uses generic visual representations as a basis to learn (task-specific) robot action policies (e.g. via behavior cloning). While the visual representations do accelerate learning, they are primarily used to encode visual observations. Thus, action information has to be derived purely from robot data, which is expensive to collect! In this work, we present a scalable alternative where the visual representations can help directly infer robot actions. We observe that vision encoders express relationships between image observations as \textit{distances} (e.g. via embedding dot product) that could be used to efficiently plan robot behavior. We operationalize this insight and develop a simple algorithm for acquiring a distance function and dynamics predictor, by fine-tuning a pre-trained representation on human collected video sequences. The final method is able to substantially outperform traditional robot learning baselines (e.g. 70% success v.s. 50% for behavior cloning on pick-place) on a suite of diverse real-world manipulation tasks. It can also generalize to novel objects, without using any robot demonstrations during train time.
@article{wang2023manipulate,
title={Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations},
author={Wang, Jianren and Dasari, Sudeep and Srirama, Mohan Kumar and Tulsiani, Shubham and Gupta, Abhinav},
journal={ICCV},
year={2023}
}
|
2022
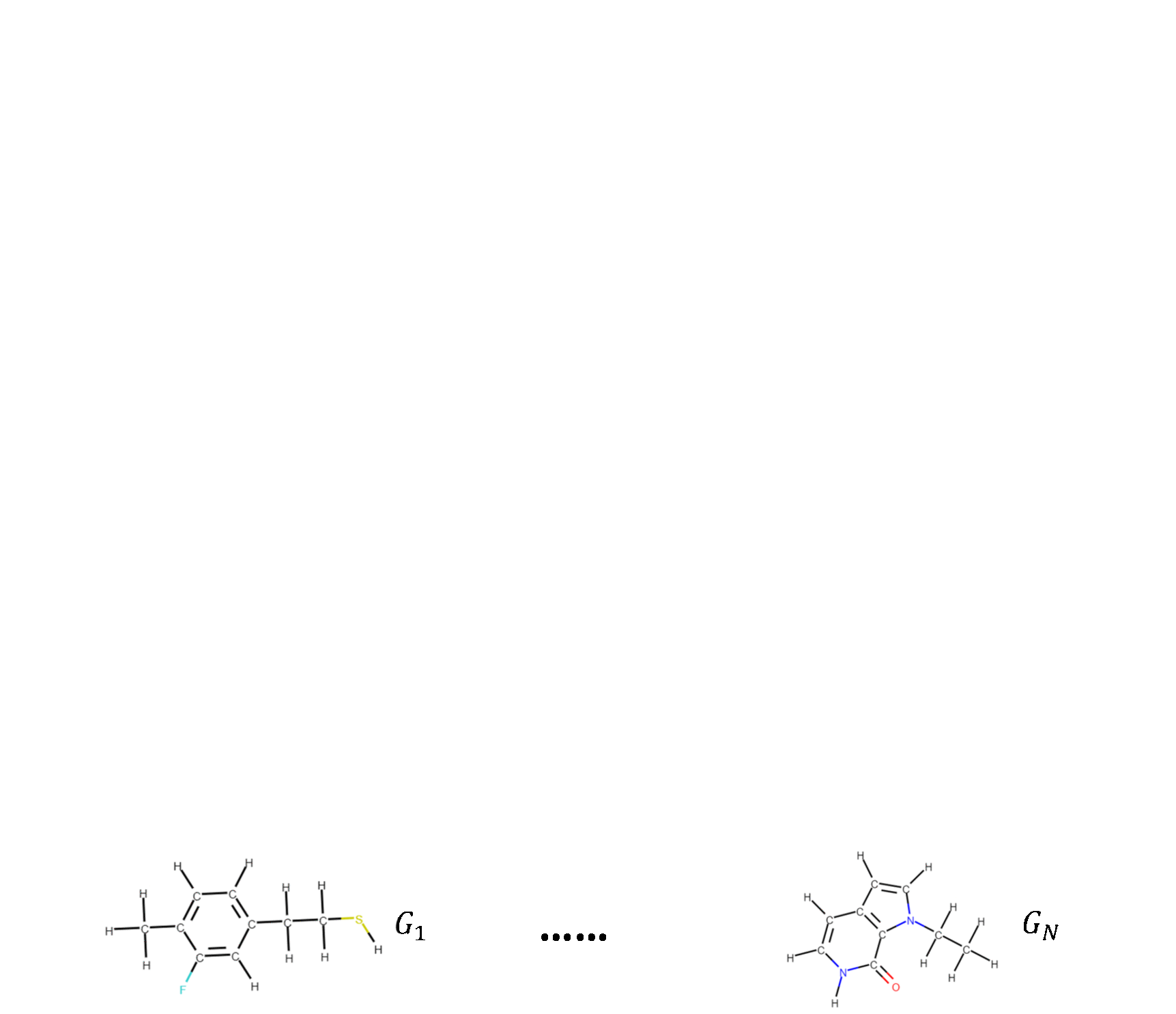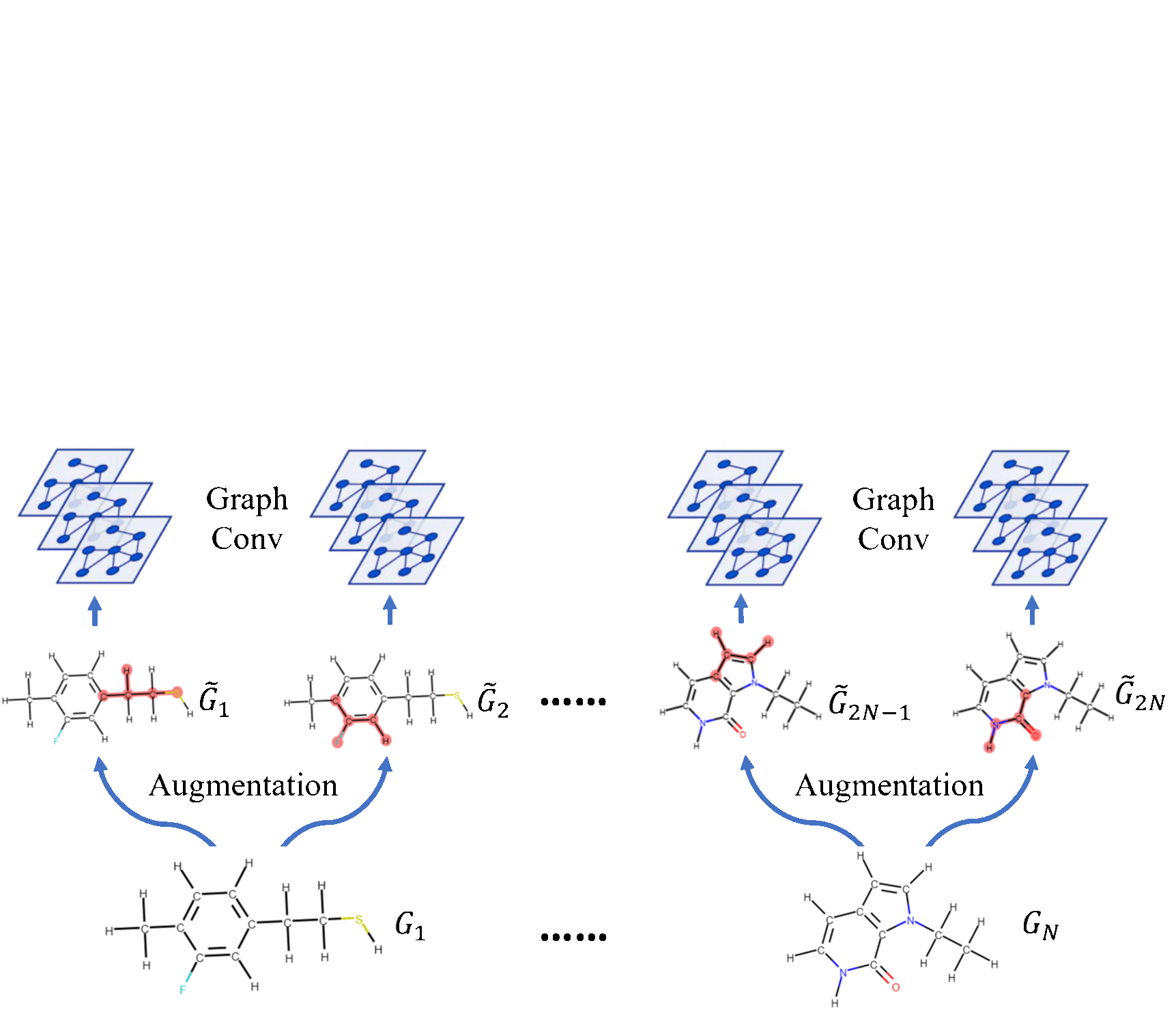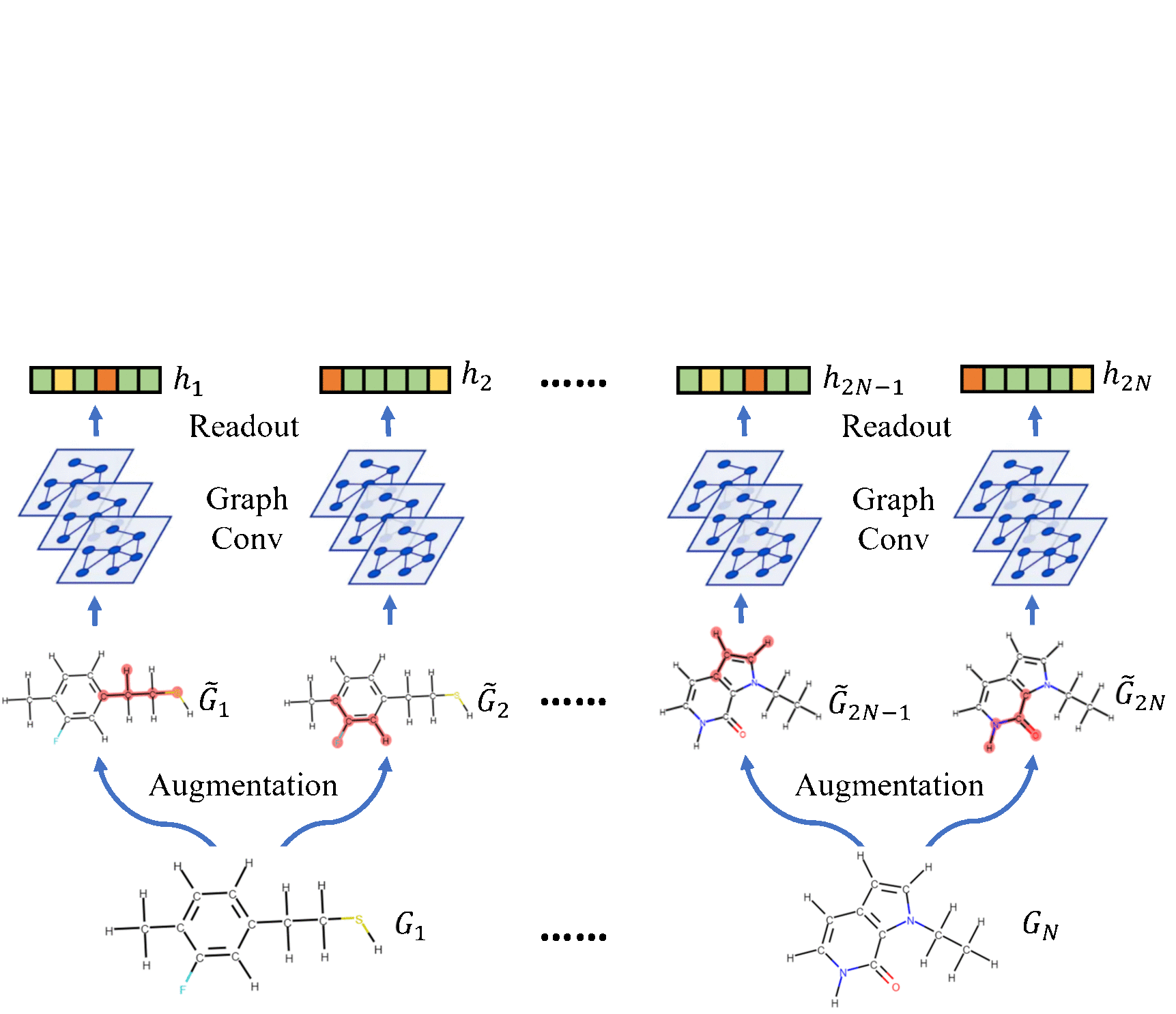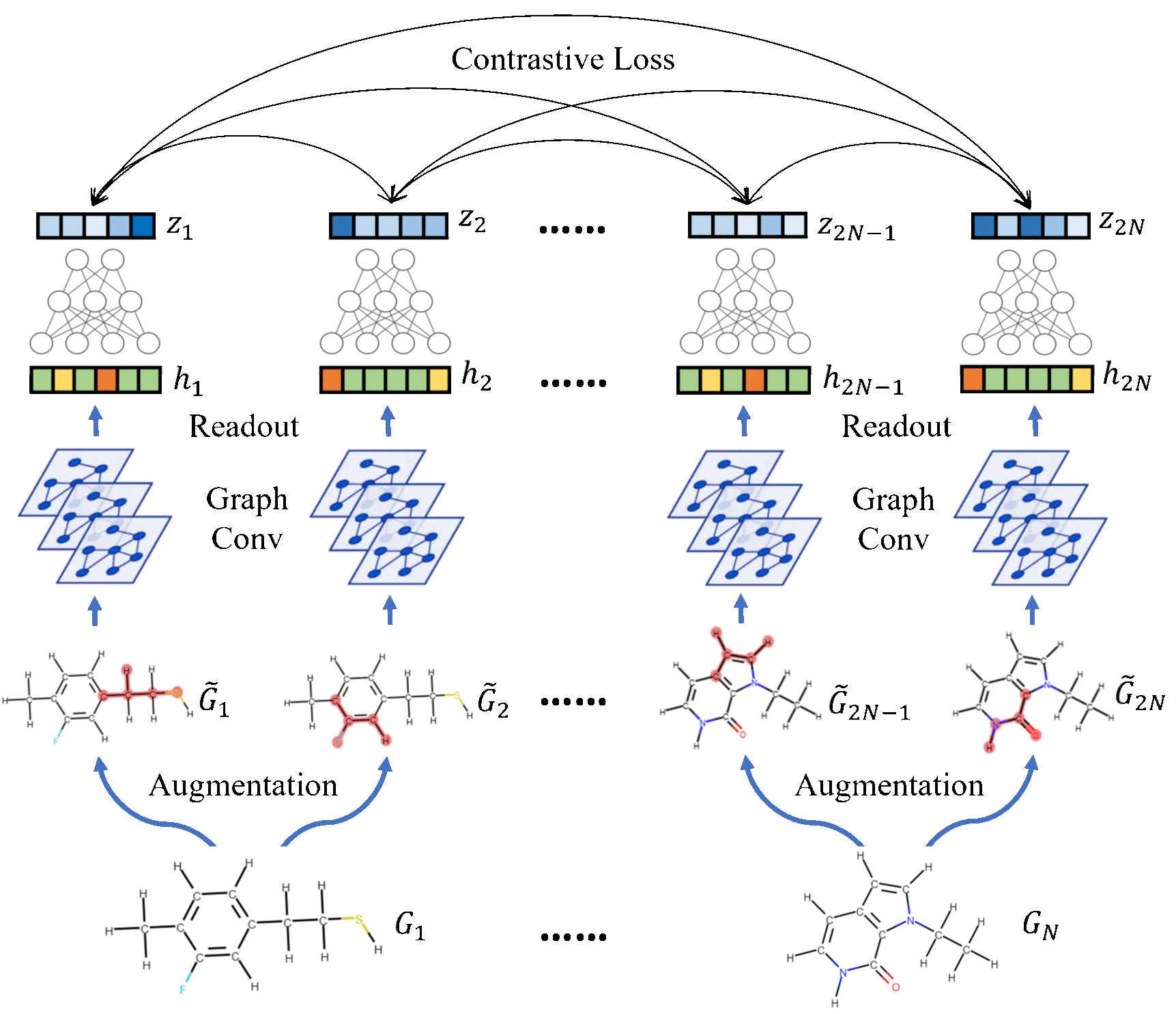 | Molecular Contrastive Learning of Representations via Graph Neural Networks Yuyang Wang, Jianren Wang, Zhonglin Cao, and Amir Barati Farimani Nature Machine Intelligence [Code] [Abstract] [Bibtex] Molecular machine learning bears promise for efficient molecule property prediction and drug discovery. However, due to the limited labeled data and the giant chemical space, machine learning models trained via supervised learning perform poorly in generalization. This greatly limits the applications of machine learning methods for molecular design and discovery. In this work, we present MolCLR: Molecular Contrastive Learning of Representations via Graph Neural Networks (GNNs), a self-supervised learning framework for large unlabeled molecule datasets. Specifically, we first build a molecular graph, where each node represents an atom and each edge represents a chemical bond. A GNN is then used to encode the molecule graph. We propose three novel molecule graph augmentations: atom masking, bond deletion, and subgraph removal. A contrastive estimator is utilized to maximize the agreement of different graph augmentations from the same molecule. Experiments show that molecule representations learned by MolCLR can be transferred to multiple downstream molecular property prediction tasks. Our method thus achieves state-of-the-art performance on many challenging datasets. We also prove the efficiency of our proposed molecule graph augmentations on supervised molecular classification tasks.
@article{wang2021molclr,
title={Molecular Contrastive Learning of Representations via Graph Neural Networks},
author={Wang, Yuyang and Wang, Jianren and Cao, Zhonglin and Farimani, Amir Barati},
journal={Nature Machine Intelligence},
year={2022}
}
|
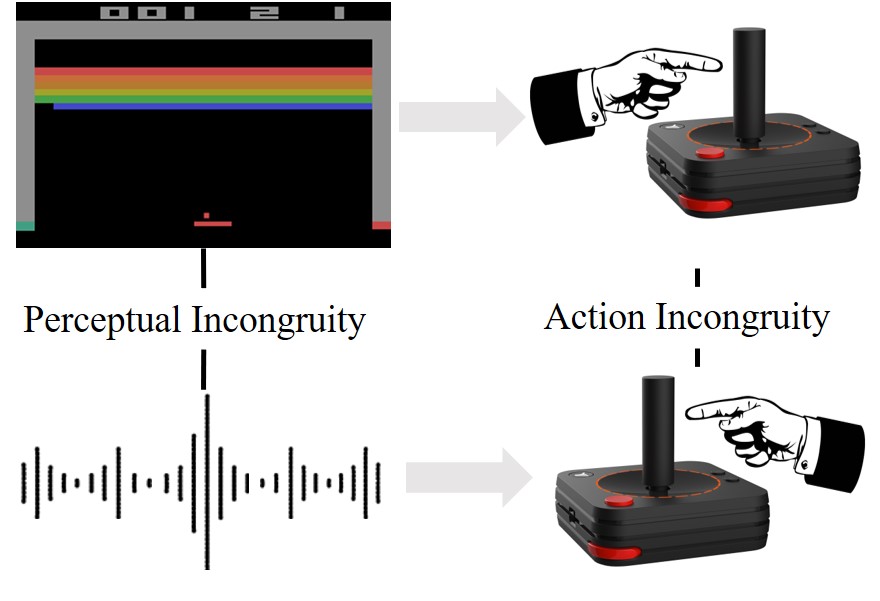 | SEMI: Self-supervised Exploration via Multisensory Incongruity Jianren Wang*, Ziwen Zhuang*, Hang Zhao 2022 IEEE International Conference on Robotics and Automation [Project Page] [Code] [Abstract] [Bibtex] Efficient exploration is a long-standing problem in reinforcement learning since extrinsic rewards are usually sparse or missing. A popular solution to this issue is to feed an agent with novelty signals as intrinsic rewards. In this work, we introduce SEMI, a self-supervised exploration policy by incentivizing the agent to maximize a new novelty signal: multisensory incongruity, which can be measured in two aspects, perception incongruity and action incongruity. The former represents the misalignment of the multisensory inputs, while the latter represents the variance of an agent's policies under different sensory inputs. Specifically, an alignment predictor is learned to detect whether multiple sensory inputs are aligned, the error of which is used to measure perception incongruity. A policy model takes different combinations of the multisensory observations as input, and outputs actions for exploration. The variance of actions is further used to measure action incongruity. Using both incongruities as intrinsic rewards, SEMI allows an agent to learn skills by exploring in a self-supervised manner without any external rewards. We further show that SEMI is compatible with extrinsic rewards and it improves sample efficiency of policy learning. The effectiveness of SEMI is demonstrated across a variety of benchmark environments including object manipulation and audio-visual games.
@article{wang2022semi,
title={SEMI: Self-supervised Exploration via Multisensory Incongruity},
author={Wang, Jianren and Zhuang, Ziwen and Zhao, Hang},
journal={IEEE International Conference on Robotics and Automation},
year={2022}
}
|
2021
 | Semi-supervised 3D Object Detection via Temporal Graph Neural Networks Jianren Wang, Haiming Gang, Siddharth Ancha, Yi-ting Chen, David Held 2021 International Conference on 3D Vision [Project Page] [Code] [Abstract] [Bibtex] 3D object detection plays an important role in autonomous driving and other robotics applications. However, these detectors usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging large amounts of unlabeled point cloud videos by semi-supervised learning of 3D object detectors via temporal graph neural networks. Our insight is that temporal smoothing can create more accurate detection results on unlabeled data, and these smoothed detections can then be used to retrain the detector. We learn to perform this temporal reasoning with a graph neural network, where edges represent the relationship between candidate detections in different time frames.
@article{wang2021sodtgnn,
title={Semi-supervised 3D Object Detection via Temporal Graph Neural Networks},
author={Wang, Jianren and Gang, Haiming and Ancha, Siddharth and Chen, Yi-ting and Held, David},
journal={International Conference on 3D Vision},
year={2021}
}
|
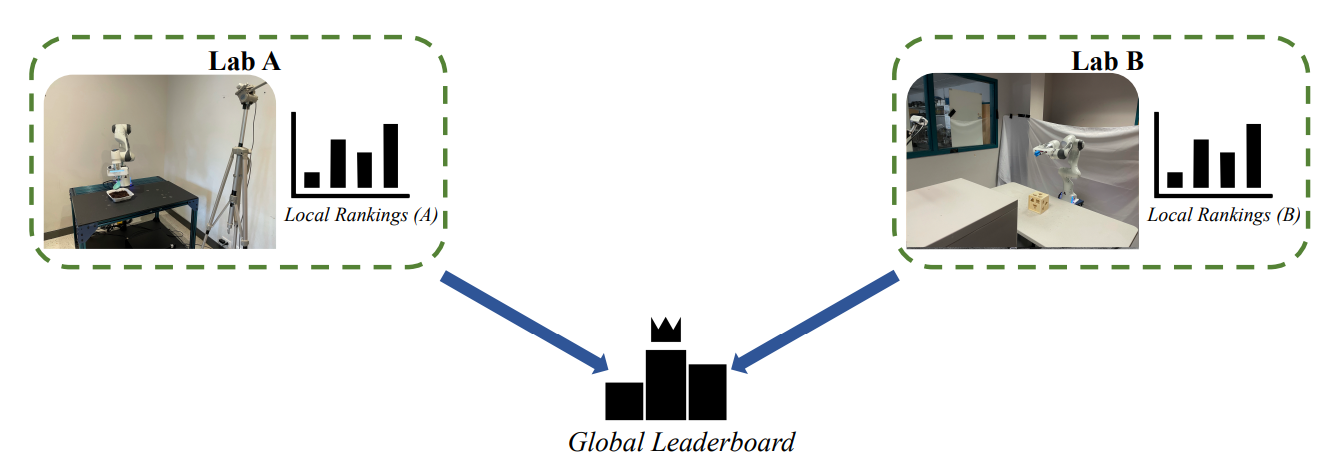 | RB2: Robotic Manipulation Benchmarking with a Twist Sudeep Dasari, Jianren Wang, Joyce Hong, Shikhar Bahl, Yixin Lin, Austin Wang Abitha Thankaraj, Karanbir Chahal, Berk Calli, Saurabh Gupta, David Held Lerrel Pinto, Deepak Pathak, Vikash Kumar, Abhinav Gupta 2021 Conference on Neural Information Processing Systems [Project Page] [Code] [Abstract] [Bibtex] Benchmarks offer a scientific way to compare algorithms using objective performance metrics. Good benchmarks have two features: (a) they should be widely useful for many research groups; (b) and they should produce reproducible findings. In robotic manipulation research, there is a trade-off between reproducibility and broad accessibility. If the benchmark is kept restrictive (fixed hardware, objects), the numbers are reproducible but the setup becomes less general. On the other hand, a benchmark could be a loose set of protocols (e.g. YCB object set) but the underlying variation in setups make the results non-reproducible. In this paper, we re-imagine benchmarking for robotic manipulation as state-of-the-art algorithmic implementations, alongside the usual set of tasks and experimental protocols. The added baseline implementations will provide a way to easily recreate SOTA numbers in a new local robotic setup, thus providing credible relative rankings between existing approaches and new work. However, these "local rankings" could vary between different setups. To resolve this issue, we build a mechanism for pooling experimental data between labs, and thus we establish a single global ranking for existing (and proposed) SOTA algorithms. Our benchmark, called Ranking-Based Robotics Benchmark (RB2), is evaluated on tasks that are inspired from clinically validated Southampton Hand Assessment Procedures. Our benchmark was run across two different labs and reveals several surprising findings. For example, extremely simple baselines like open-loop behavior cloning, outperform more complicated models (e.g. closed loop, RNN, Offline-RL, etc.) that are preferred by the field. We hope our fellow researchers will use \name to improve their research's quality and rigor.
@article{wang2021aril,
title={RB2: Robotic Manipulation Benchmarking with a Twist},
author={Dasari, Sudeep and Wang, Jianren and ... and Gupta, Saurabh and Held, David and Pinto, Lerrel and Pathak, Deepak and Kumar, Vikash and Gupta, Abhinav},
journal={Thirty-fifth Conference on Neural Information Processing Systems},
year={2021}
}
|
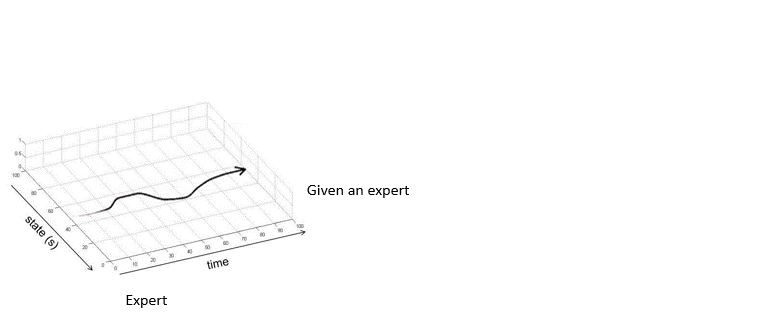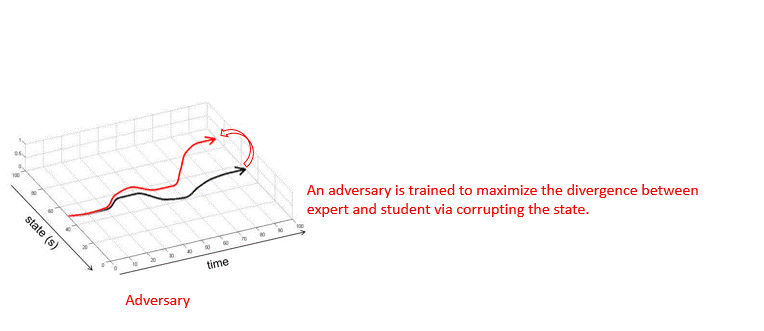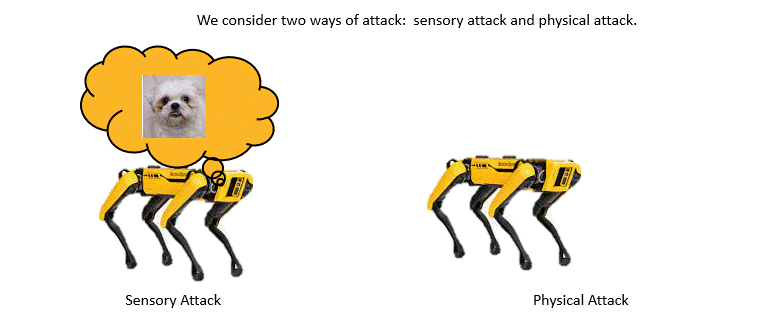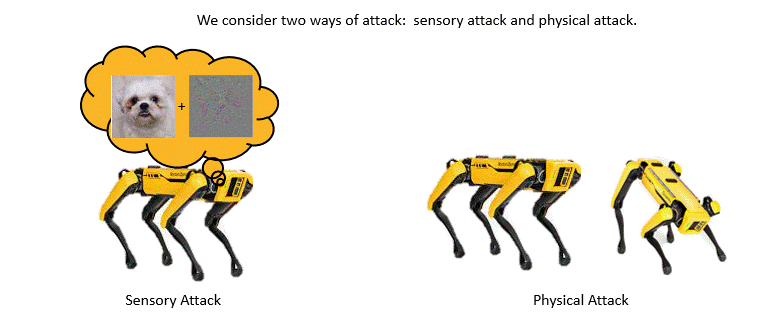 | Adversarially Robust Imitation Learning Jianren Wang, Ziwen Zhuang, Yuyang Wang, Hang Zhao 2021 Conference on Robot Learning [Project Page] [Code] [Abstract] [Bibtex] Modern imitation learning (IL) utilizes deep neural networks (DNNs) as function approximators to mimic the policy of the expert demonstrations. However, DNNs can be easily fooled by subtle noise added to the input, which is even non-detectable by humans. This makes the learned agent vulnerable to attacks, especially in IL where agents can struggle to recover from the errors. In such light, we propose a sound Adversarially Robust Imitation Learning (ARIL) method. In our setting, an agent and an adversary are trained alternatively. The former with adversarially attacked input at each timestep mimics the behavior of an online expert and the latter learns to add perturbations on the states by forcing the learned agent to fail on choosing the right decisions. We theoretically prove that ARIL can achieve adversarial robustness and evaluate ARIL on multiple benchmarks from DM Control Suite. The result reveals that our method (ARIL) achieves better robustness compare with other imitation learning methods under both sensory attack and physical attack.
@article{wang2021aril,
title={Adversarially Robust Imitation Learning},
author={Wang, Jianren and Zhuang, Ziwen and Wang, Yuyang and Zhao, Hang},
journal={CORL},
year={2021}
}
|
 | Wanderlust: Online Continual Object Detection in the Real World Jianren Wang, Xin Wang, Yue Shang-Guan, Abhinav Gupta 2021 International Conference on Computer Vision [Project Page] [Code] [Abstract] [Bibtex] Online continual learning from data streams in dynamic environments is a critical direction in the computer vision field. However, realistic benchmarks and fundamental studies in this line are still missing. To bridge the gap, we present a new online continual object detection benchmark with an egocentric video dataset, Objects Around Krishna (OAK). OAK adopts the KrishnaCAM videos, an ego-centric video stream collected over nine months by a graduate student. OAK provides exhaustive bounding box annotations of 80 video snippets (~17.5 hours) for 105 object categories in outdoor scenes. The emergence of new object categories in our benchmark follows a pattern similar to what a single person might see in their day-to-day life. The dataset also captures the natural distribution shifts as the person travels to different places. These egocentric long running videos provide a realistic playground for continual learning algorithms, especially in online embodied settings. We also introduce new evaluation metrics to evaluate the model performance and catastrophic forgetting and provide baseline studies for online continual object detection. We believe this benchmark will pose new exciting challenges for learning from non-stationary data in continual learning.
@article{wang2021wanderlust,
title={Wanderlust: Online Continual Object Detection in the Real World},
author={Wang, Jianren and Wang, Xin and Shang-Guan, Yue and Gupta, Abhinav},
journal={ICCV},
year={2021}
}
|
2020
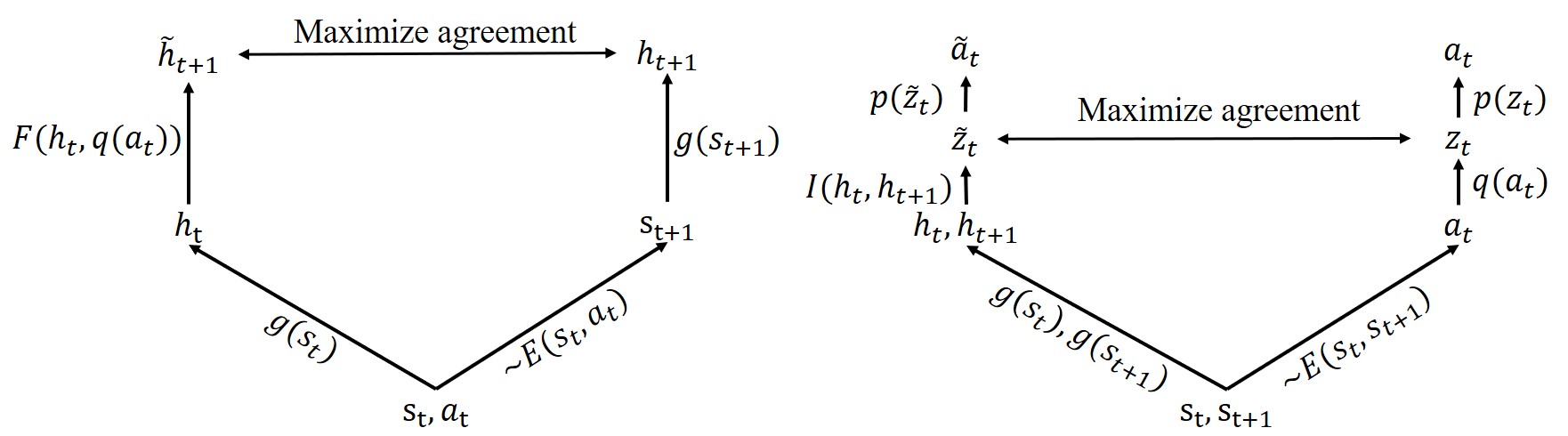 | CLOUD: Contrastive Learning of Unsupervised Dynamics Jianren Wang*, Yujie Lu*, Hang Zhao 2020 Conference on Robot Learning [Project Page] [Code] [Abstract] [Bibtex] Developing agents that can perform complex control tasks from high dimensional observations such as pixels is challenging due to difficulties in learning dynamics efficiently. In this work, we propose to learn forward and inverse dynamics in a fully unsupervised manner via contrastive estimation. Specifically, we train a forward dynamics model and an inverse dynamics model in the feature space of states and actions with data collected from random exploration. Unlike most existing deterministic models, our energy-based model takes into account the stochastic nature of agent-environment interactions. We demonstrate the efficacy of our approach across a variety of tasks including goal-directed planning and imitation from observations.
@inproceedings{jianren20cloud,
Author = {Wang, Jianren and Lu, Yujie and Zhao, Hang},
Title = {CLOUD: Contrastive Learning of Unsupervised Dynamics},
Booktitle = {CORL},
Year = {2020}
}
|
 | Inverting the Forecasting Pipeline with SPF2: Sequential Pointcloud Forecasting for Sequential Pose Forecasting Xinshuo Weng, Jianren Wang, Sergey Levine, Kris Kitani, Nick Rhinehart 2020 Conference on Robot Learning [Project Page] [Code] [Abstract] [Bibtex] Many autonomous systems forecast aspects of the future in order to aid decision-making. For example, self-driving vehicles and robotic manipulation systems often forecast future object poses by first detecting and tracking objects. However, this detect-then-forecast pipeline is expensive to scale, as pose forecasting algorithms typically require labeled sequences of object poses, which are costly to obtain in 3D space. Can we scale performance without requiring additional labels? We hypothesize yes, and propose inverting the detect-then-forecast pipeline. Instead of detecting, tracking and then forecasting the objects, we propose to first forecast 3D sensor data (e.g., point clouds with $100$k points) and then detect/track objects on the predicted point cloud sequences to obtain future poses, i.e., a forecast-then-detect pipeline. This inversion makes it less expensive to scale pose forecasting, as the sensor data forecasting task requires no labels. Part of this work's focus is on the challenging first step -- Sequential Pointcloud Forecasting (SPF), for which we also propose an effective approach, SPFNet. To compare our forecast-then-detect pipeline relative to the detect-then-forecast pipeline, we propose an evaluation procedure and two metrics. Through experiments on a robotic manipulation dataset and two driving datasets, we show that SPFNet is effective for the SPF task, our forecast-then-detect pipeline outperforms the detect-then-forecast approaches to which we compared, and that pose forecasting performance improves with the addition of unlabeled data.
@article{Weng2020_SPF2,
author = {Weng, Xinshuo and Wang, Jianren and Levine, Sergey
and Kitani, Kris and Rhinehart, Nick},
journal = {CoRL},
title = {Inverting the Pose Forecasting Pipeline with SPF2:
Sequential Pointcloud Forecasting for Sequential Pose Forecasting},
year = {2020}
}
|
 | PanoNet3D: Combining Semantic and Geometric Understanding for LiDARPoint Cloud Detection Xia Chen, Jianren Wang, David Held, Martial Hebert 2020 International Virtual Conference on 3D Vision [Project Page] [Code] [Abstract] [Bibtex] Visual data in autonomous driving perception, such as camera image and LiDAR point cloud, can be interpreted as a mixture of two aspects: semantic feature and geometric structure. Semantics come from the appearance and context of objects to the sensor, while geometric structure is the actual 3D shape of point clouds. Most detectors on LiDAR point clouds focus only on analyzing the geometric structure of objects in real 3D space. Unlike previous works, we propose to learn both semantic feature and geometric structure via a unified multi-view framework. Our method exploits the nature of LiDAR scans -- 2D range images, and applies well-studied 2D convolutions to extract semantic features. By fusing semantic and geometric features, our method outperforms state-of-the-art approaches in all categories by a large margin. The methodology of combining semantic and geometric features provides a unique perspective of looking at the problems in real-world 3D point cloud detection.
@inproceedings{xia20panonet3d,
Author = {Chen, Xia and Wang, Jianren and Held, David and Hebert, Martial},
Title = {PanoNet3D: Combining Semantic and Geometric Understanding
for LiDARPoint Cloud Detection},
Booktitle = {3DV},
Year = {2020}
}
|
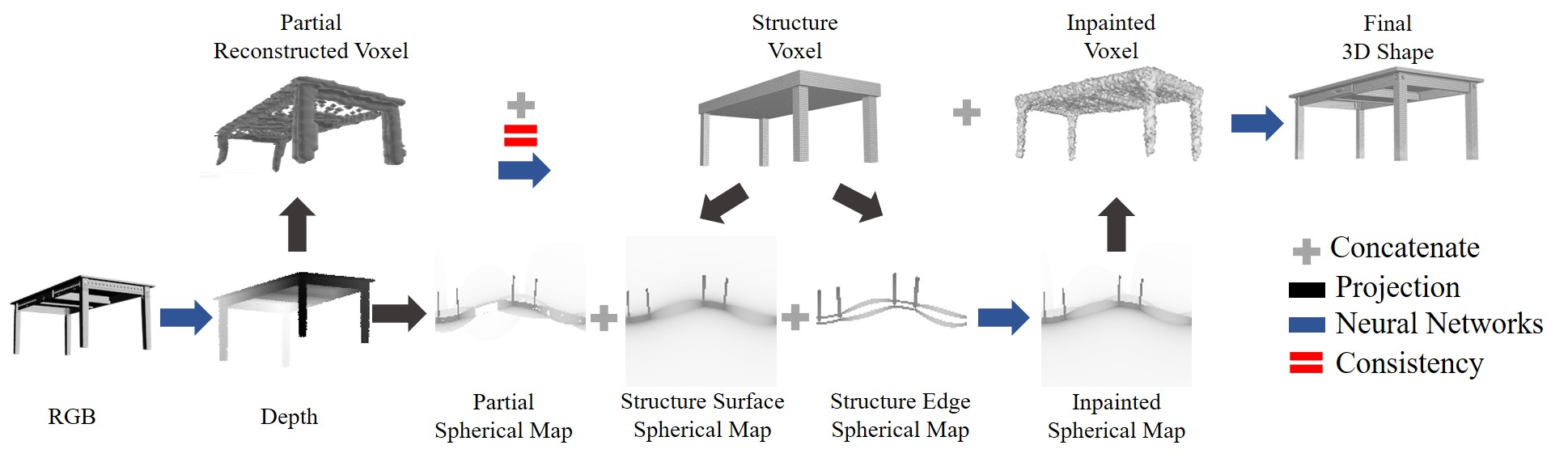 | GSIR: Generalizable 3D Shape Interpretation and Reconstruction Jianren Wang, Zhaoyuan Fang 2020 The European Conference on Computer Vision [Project Page] [Code] [Abstract] [Bibtex] 3D shape interpretation and reconstruction are closely related to each other but have long been studied separately and often end up with priors that are highly biased towards the training classes. In this paper, we present an algorithm, Generalizable 3D Shape Interpretation and Reconstruction (GSIR), designed to jointly learn these two tasks to capture generic, class-agnostic shape priors for a better understanding of 3D geometry. We propose to recover 3D shape structures as cuboids from partial reconstruction and use the predicted structures to further guide full 3D reconstruction. The unified framework is trained simultaneously offline to learn a generic notion and can be fine-tuned online for specific objects without any annotations. Extensive experiments on both synthetic and real data demonstrate that introducing 3D shape interpretation improves the performance of single image 3D reconstruction and vice versa, achieving the state-of-the-art performance on both tasks for objects in both seen and unseen categories.
@inproceedings{wang2020gsir,
title={GSIR: Generalizable 3D Shape Interpretation and Reconstruction},
author={Wang, Jianren and Fang, Zhaoyuan},
booktitle={European Conference on Computer Vision},
pages={498--514},
year={2020},
organization={Springer}
}
|
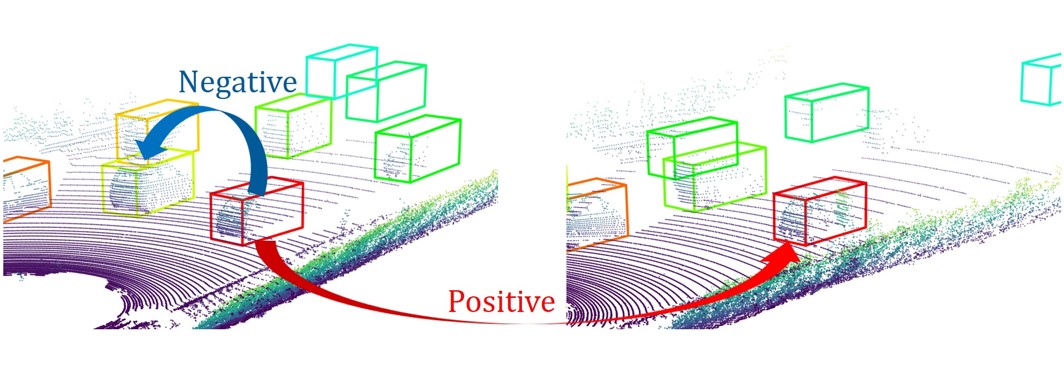 | Uncertainty-aware Self-supervised 3D Data Association Jianren Wang, Siddharth Ancha, Yi-Ting Chen, David Held 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems [Project Page] [Code] [Abstract] [Bibtex] 3D object trackers usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging vast unlabeled datasets by self-supervised metric learning of 3D object trackers, with a focus on data association. Large scale annotations for unlabeled data are cheaply obtained by automatic object detection and association across frames. We show how these self-supervised annotations can be used in a principled manner to learn point-cloud embeddings that are effective for 3D tracking. We estimate and incorporate uncertainty in self-supervised tracking to learn more robust embeddings, without needing any labeled data. We design embeddings to differentiate objects across frames, and learn them using uncertainty-aware self-supervised training. Finally, we demonstrate their ability to perform accurate data association across frames, towards effective and accurate 3D tracking.
@inproceedings{jianren20s3da,
Author = {Wang, Jianren and Ancha, Siddharth and Chen, Yi-Ting and Held, David},
Title = {Uncertainty-aware Self-supervised 3D Data Association},
Booktitle = {IROS},
Year = {2020}
}
|
 | Motion Prediction in Visual Object Tracking Jianren Wang*, Yihui He* 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems [Abstract] [Bibtex] Visual object tracking (VOT) is an essential component for many applications, such as autonomous driving or assistive robotics. However, recent works tend to develop accurate systems based on more computationally expensive feature extractors for better instance matching. In contrast, this work addresses the importance of motion prediction in VOT. We use an off-the-shelf object detector to obtain instance bounding boxes. Then, a combination of camera motion decouple and Kalman filter is used for state estimation. Although our baseline system is a straightforward combination of standard methods, we obtain state-of-the-art results. Our method establishes new state-of-the-art performance on VOT (VOT-2016 and VOT-2018). Our proposed method improves the EAO on VOT-2016 from 0.472 of prior art to 0.505, from 0.410 to 0.431 on VOT-2018. To show the generalizability, we also test our method on video object segmentation (VOS: DAVIS-2016 and DAVIS-2017) and observe consistent improvement.
@inproceedings{wang2020mt,
Author = {Wang, Jianren and He, Yihui},
Title = {Motion Prediction in Visual Object Tracking},
Booktitle = {IROS},
Year = {2020}
}
|
 | Deep Mixture Density Network for Object Detection under Occlusion Yihui He*, Jianren Wang* 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems [Abstract] [Bibtex] Mistakes/uncertainties in object detection could lead to catastrophes when deploying robots in the real world. In this paper, we measure the uncertainties of object localization to minimize this kind of risk. Uncertainties emerge upon challenging cases like occlusion. The bounding box borders of an occluded object can have multiple plausible configurations. We propose a deep multivariate mixture of Gaussians model for probabilistic object detection. The covariances help to learn the relationship between the borders, and the mixture components potentially learn different configurations of an occluded part. Quantitatively, our model improves the AP of the baselines by 3.9% and 1.4% on CrowdHuman and MS-COCO respectively with almost no computational or memory overhead. Qualitatively, our model enjoys explainability since the resulting covariance matrices and the mixture components help measure uncertainties.
@inproceedings{wang2020mix,
Author = {Wang, Jianren and He, Yihui},
Title = {Deep Mixture Density Network for Object Detection under Occlusion},
Booktitle = {IROS},
Year = {2020}
}
|
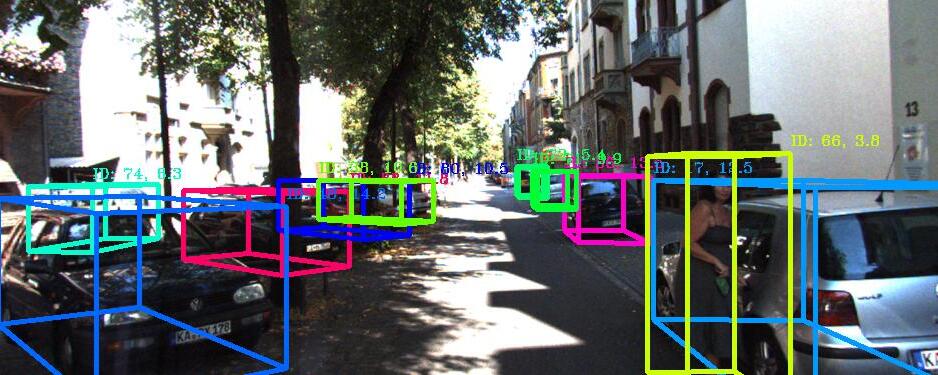 | 3D Multi-Object Tracking: A Baseline and New Evaluation Metrics Xinshuo Weng, Jianren Wang, David Held, Kris M. Kitani 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems [Project Page] [Code] [Abstract] [Bibtex] 3D multi-object tracking (MOT) is an essential component for many applications such as autonomous driving and assistive robotics. Recent work on 3D MOT focuses on developing accurate systems giving less attention to practical considerations such as computational cost and system complexity. In contrast, this work proposes a simple real-time 3D MOT system. Our system first obtains 3D detections from a LiDAR point cloud. Then, a straightforward combination of a 3D Kalman filter and the Hungarian algorithm is used for state estimation and data association. Additionally, 3D MOT datasets such as KITTI evaluate MOT methods in the 2D space and standardized 3D MOT evaluation tools are missing for a fair comparison of 3D MOT methods. Therefore, we propose a new 3D MOT evaluation tool along with three new metrics to comprehensively evaluate 3D MOT methods. We show that, although our system employs a combination of classical MOT modules, we achieve state-of-the-art 3D MOT performance on two 3D MOT benchmarks (KITTI and nuScenes). Surprisingly, although our system does not use any 2D data as inputs, we achieve competitive performance on the KITTI 2D MOT leaderboard. Our proposed system runs at a rate of 207.4 FPS on the KITTI dataset, achieving the fastest speed among all modern MOT systems.
@article{Weng2020_AB3DMOT,
author = {Weng, Xinshuo and Wang, Jianren and Held, David and Kitani, Kris},
journal = {IROS},
title = {3D Multi-Object Tracking: A Baseline and New Evaluation Metrics},
year = {2020}
}
|
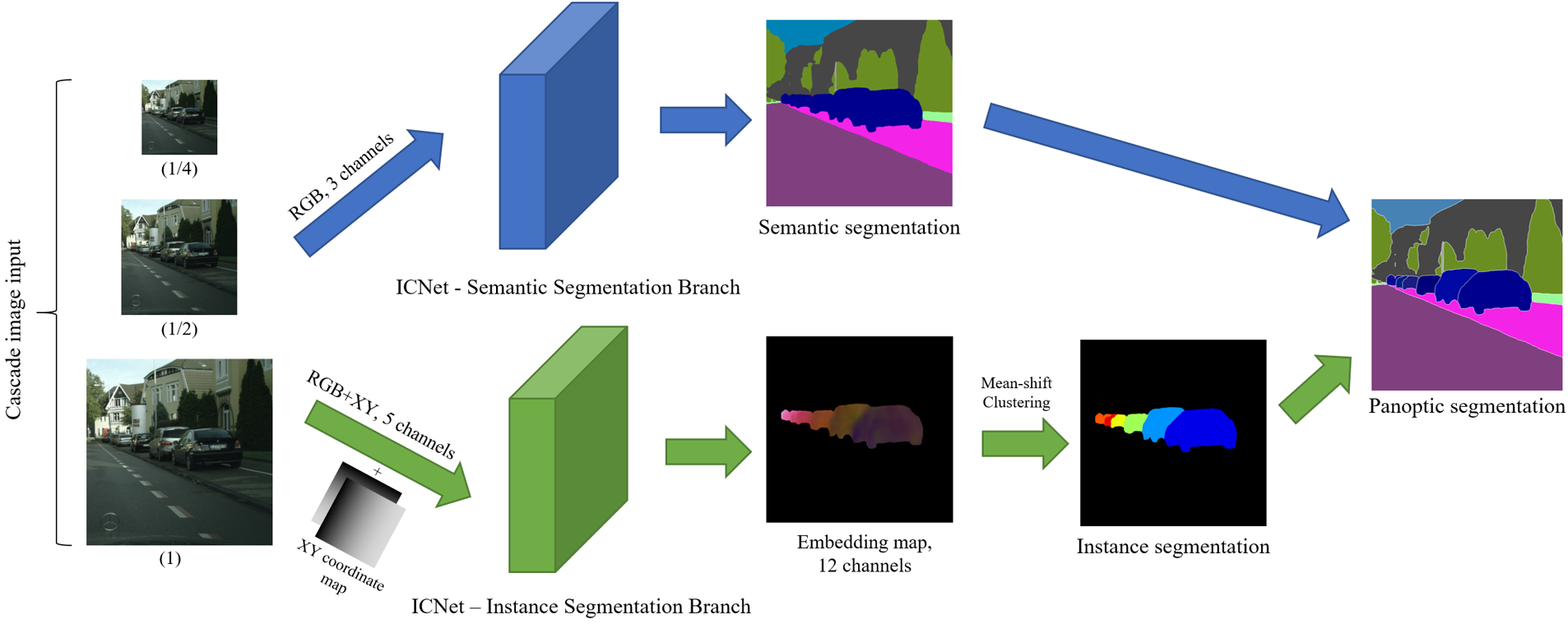 | PanoNet: Real-time Panoptic Segmentation through Position-Sensitive Feature Embedding Xia Chen, Jianren Wang, Martial Hebert [Abstract] [Bibtex] We propose a simple, fast, and flexible framework to generate simultaneously semantic and instance masks for panoptic segmentation. Our method, called PanoNet, incorporates a clean and natural structure design that tackles the problem purely as a segmentation task without the time-consuming detection process. We also introduce position-sensitive embedding for instance grouping by accounting for both object's appearance and its spatial location. Overall, PanoNet yields high panoptic quality results of high-resolution Cityscapes images in real-time, significantly faster than all other methods with comparable performance. Our approach well satisfies the practical speed and memory requirement for many applications like autonomous driving and augmented reality.
@article{Chen2020_PanoNet,
author = {Chen, Xia and Wang, Jianren and Hebert, Martial},
journal = {arXiv},
title = {PanoNet: Real-time Panoptic Segmentation through Position-Sensitive Feature Embedding},
year = {2020}
}
|
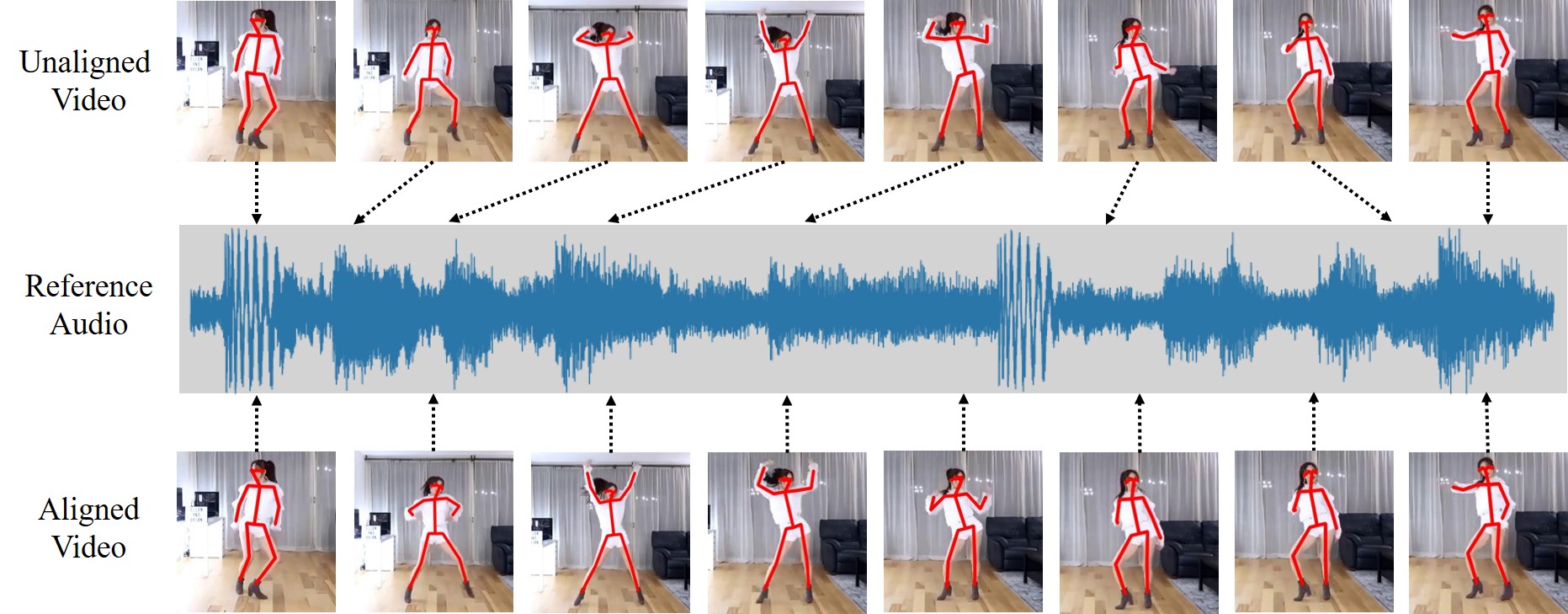 | AlignNet: A Unifying Approach to Audio-Visual Alignment Jianren Wang*, Zhaoyuan Fang*, Hang Zhao 2020 Winter Conference on Applications of Computer Vision [Project Page] [Code] [Data] [Abstract] [Bibtex] We present AlignNet, a model designed to synchronize a video with a reference audio under non-uniform and irregular misalignment. AlignNet learns the end-to-end dense correspondence between each frame of a video and an audio. Our method is designed according to simple and well-established principles: attention, pyramidal processing, warping, and affinity function. Together with the model, we release a dancing dataset Dance50 for training and evaluation. Qualitative, quantitative and subjective evaluation results on dance-music alignment and speech-lip alignment demonstrate that our method far outperforms the state-of-the-art methods.
@inproceedings{jianren20alignnet,
Author = {Wang, Jianren and Fang, Zhaoyuan
and Zhao, Hang},
Title = {AlignNet: A Unifying Approach to Audio-Visual Alignment},
Booktitle = {WACV},
Year = {2020}
}
|
2019
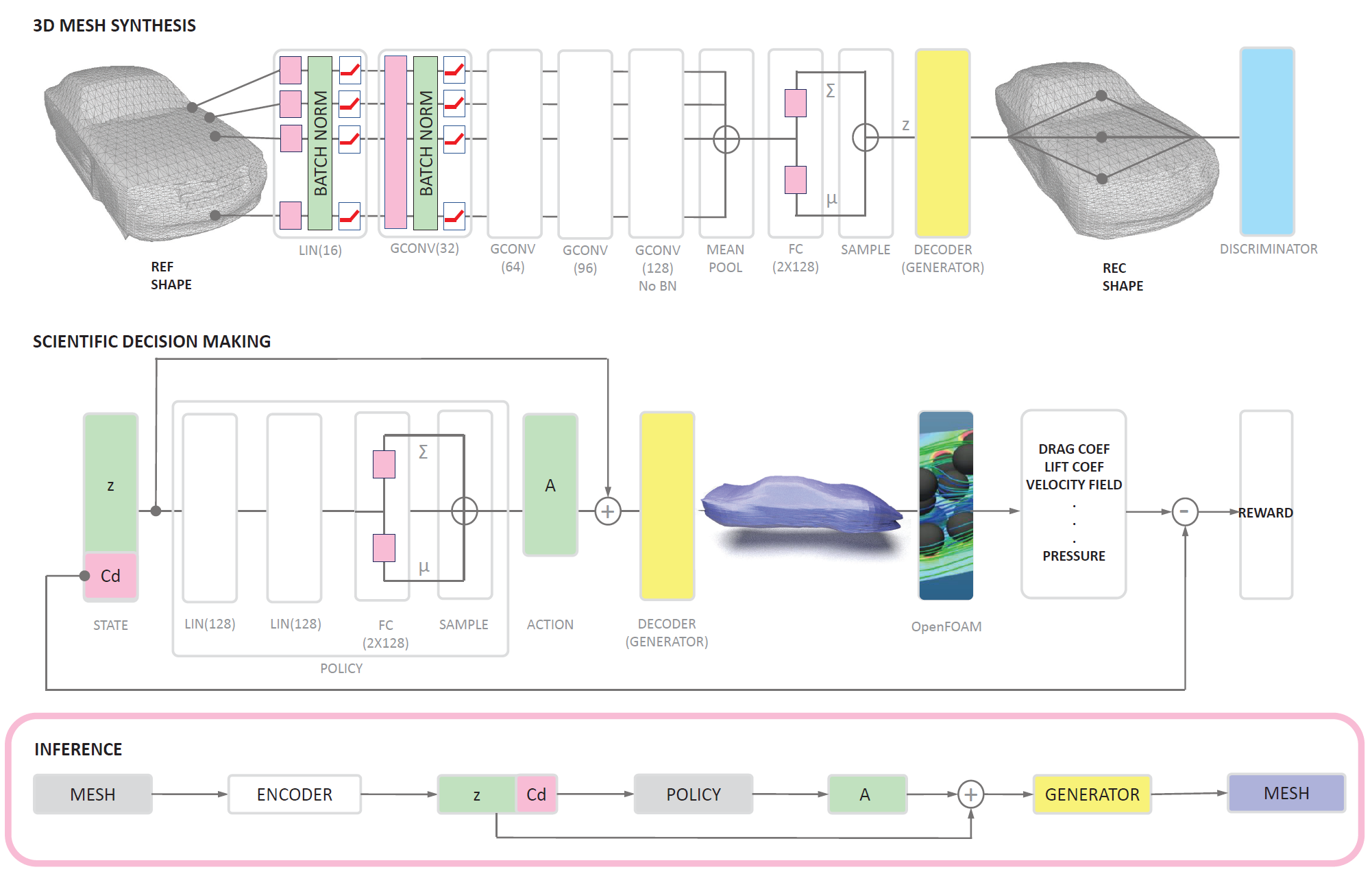 | Physics-Aware 3D Mesh Synthesis Jianren Wang, Yihui He 2019 International Conference on 3D Vision [Abstract] [Bibtex] This paper proposes a new task that emphasizes the importance of past-designs in 3D mesh synthesis. Instead of synthesizing novel meshes from scratch, we introduce a physics-aware 3D mesh synthesis algorithm, which consists of two modules: a 3D mesh synthesis module where we use a VAEGAN to encode 3D meshes into a latent variable and use the decoder to generate 3D meshes from the encoded representations; a scientific decision making module using reinforcement learning which alters the latent representation supervised by a provided physical constraint. The results show that our approach can modify a given mesh so that it satisfies external physical property constraints while maintaining high appearance similarity. More importantly, our method outperforms all baseline methods by a large margin.
@inproceedings{wang2019pams,
Author = {Wang, Jianren and He, Yihui},
Title = {Physics-Aware 3D Mesh Synthesis},
Booktitle = {3DV},
Year = {2019}
}
|
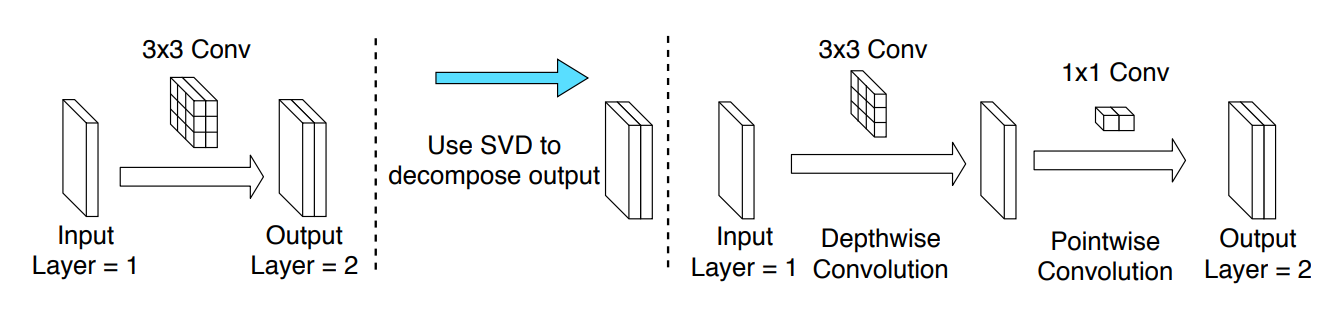 | Depth-wise Decomposition for Accelerating Separable Convolutions in Efficient Convolutional Neural Networks Yihui He*, Jianing Qian*, Jianren Wang 2019 IEEE Conference on Computer Vision and Pattern Recognition Workshop |
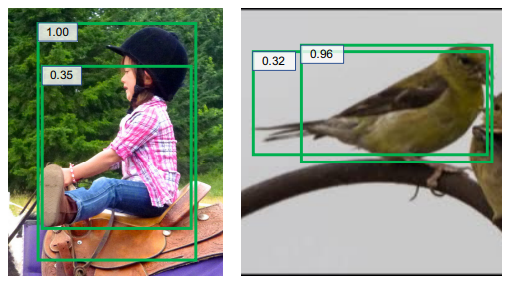 | Bounding Box Regression with Uncertainty for Accurate Object Detection Yihui He, Chenchen Zhu, Jianren Wang, Marios Savvides, Xiangyu Zhang 2019 IEEE Conference on Computer Vision and Pattern Recognition [Code] |
2018
 | Vertical Jump Height Estimation Algorithm Based on Takeoff and Landing Identification Via Foot-Worn Inertial Sensing Jianren Wang, Junkai Xu, Peter B Shull 2018 Journal of biomechanical engineering |
 | Integration of a Low-Cost Three-Axis Sensor for Robot Force Control Shuyang Chen, Jianren Wang, Peter Kazanzides 2018 Second IEEE International Conference on Robotic Computing |
2017
 | Prioritization and static error compensation for multi-camera collaborative tracking in augmented reality Jianren Wang, Long Qian, Ehsan Azimi, Peter Kazanzides 2017 IEEE Virtual Reality |
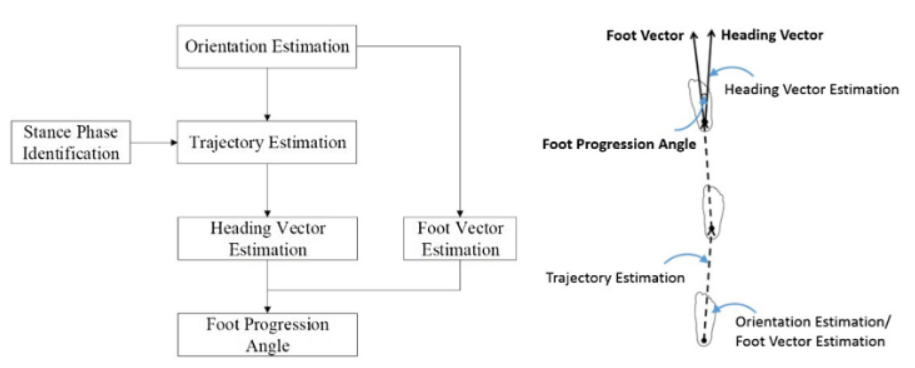 | Validation of a smart shoe for estimating foot progression angle during walking gait Haisheng Xia, Junkai Xu, Jianren Wang, Michael A Hunt, Peter B Shull 2017 Journal of biomechanics |