
Publications
You can also find my articles on my Google Scholar Profile.Show selected / Show all by date / Show all by topic
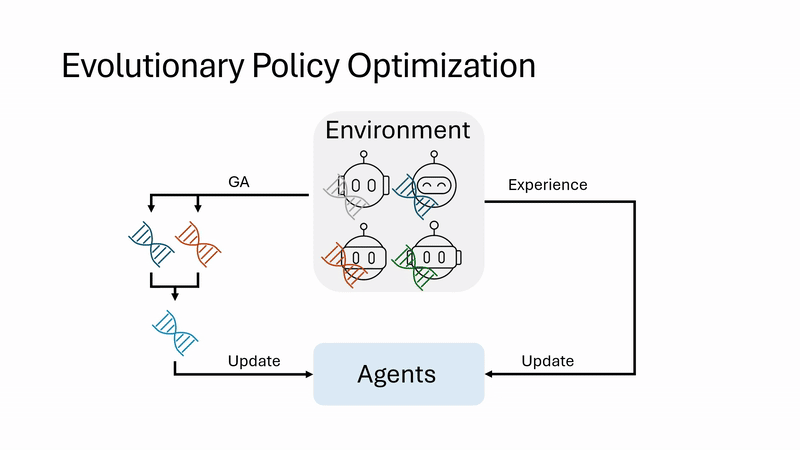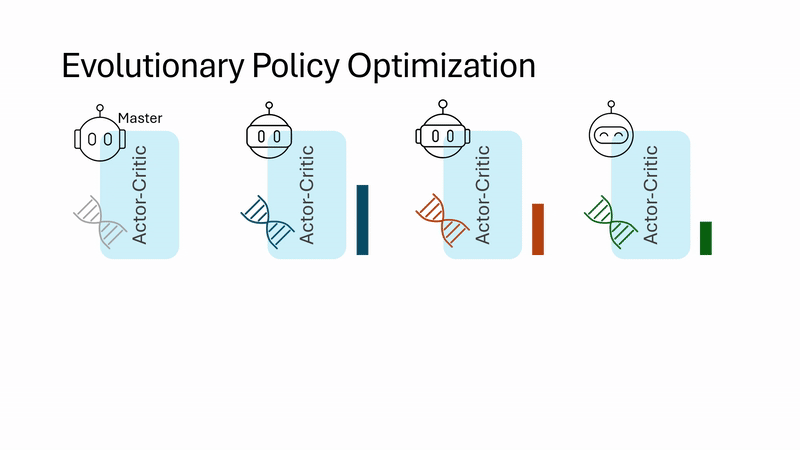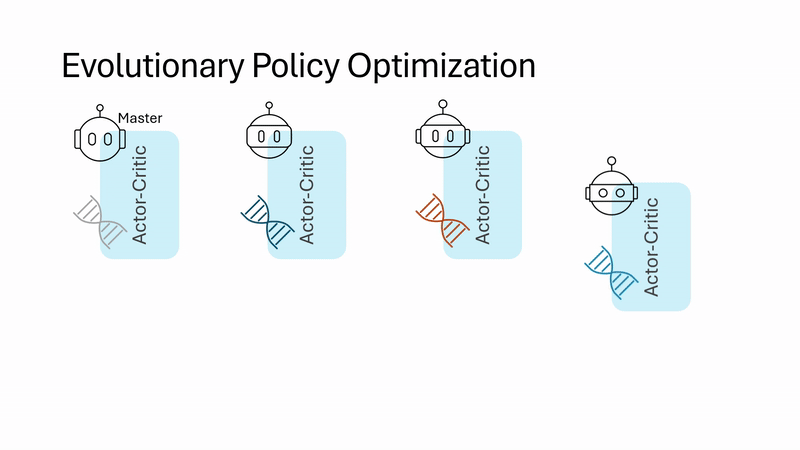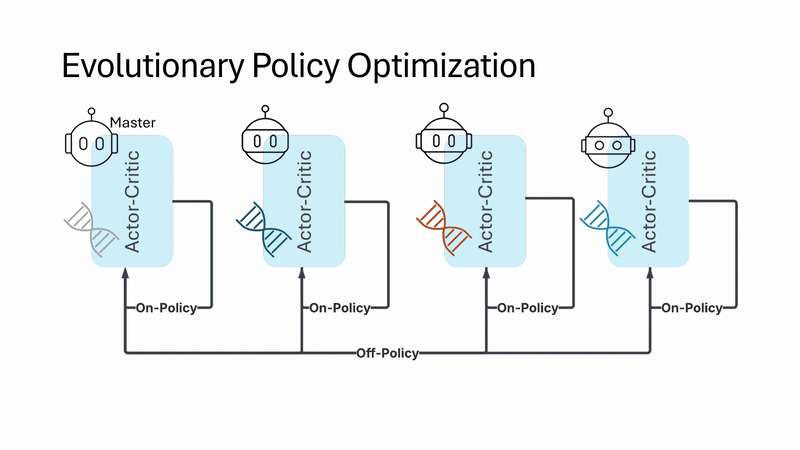 | Evolutionary Policy Optimization Jianren Wang*, Yifan Su*, Abhinav Gupta, Deepak Pathak Preprint [Project Page] [Code] [Abstract] [Bibtex] On-policy reinforcement learning (RL) algorithms are widely used for their strong asymptotic performance and training stability, but they struggle to scale with larger batch sizes, as additional parallel environments yield redundant data due to limited policy-induced diversity. In contrast, Evolutionary Algorithms (EAs) scale naturally and encourage exploration via randomized population-based search, but are often sample-inefficient. We propose Evolutionary Policy Optimization (EPO), a hybrid algorithm that combines the scalability and diversity of EAs with the performance and stability of policy gradients. EPO maintains a population of agents conditioned on latent variables, shares actor-critic network parameters for coherence and memory efficiency, and aggregates diverse experiences into a master agent. Across tasks in dexterous manipulation, legged locomotion, and classic control, EPO outperforms state-of-the-art baselines in sample efficiency, asymptotic performance, and scalability.
@article{wang2025evolutionary,
title={Evolutionary Policy Optimization},
author={Wang, Jianren and Su, Yifan and Gupta, Abhinav and Pathak, Deepak},
journal={arXiv preprint arXiv:2503.19037},
year={2025}
}
|
 | Robot Parkour Learning Ziwen Zhuang*, Zipeng Fu*, Jianren Wang, Christopher Atkeson, Soren Schwertfeger, Chelsea Finn, Hang Zhao 2023 Conference on Robot Learning (Best Systems Paper Finalist) [Project Page] [Code] [Abstract] [Bibtex] Parkour is a grand challenge for legged locomotion that requires robots to overcome various obstacles rapidly in complex environments. Existing methods can generate either diverse but blind locomotion skills or vision-based but specialized skills by using reference animal data or complex rewards. However, autonomous parkour requires robots to learn generalizable skills that are both vision-based and diverse to perceive and react to various scenarios. In this work, we propose a system for learning a single end-to-end vision-based parkour policy of diverse parkour skills using a simple reward without any reference motion data. We develop a reinforcement learning method inspired by direct collocation to generate parkour skills, including climbing over high obstacles, leaping over large gaps, crawling beneath low barriers, squeezing through thin slits, and running. We distill these skills into a single vision-based parkour policy and transfer it to a quadrupedal robot using its egocentric depth camera. We demonstrate that our system can empower two different low-cost robots to autonomously select and execute appropriate parkour skills to traverse challenging real-world environments.
@article{zhuang2023parkour,
title={Robot Parkour Learning},
author={Zhuang, Ziwen and Fu, Zipeng and Wang, Jianren and Atkeson, Christopher and Schwertfeger, Soren and Finn, Chelsea and Zhao, Hang},
journal={CoRL},
year={2023}
}
|
 | Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations Jianren Wang*, Sudeep Dasari*, Mohan Kumar, Shubham Tulsiani, Abhinav Gupta 2023 International Conference on Computer Vision (Oral) [Project Page] [Code] [Abstract] [Bibtex] The field of visual representation learning has seen explosive growth in the past years, but its benefits in robotics have been surprisingly limited so far. Prior work uses generic visual representations as a basis to learn (task-specific) robot action policies (e.g. via behavior cloning). While the visual representations do accelerate learning, they are primarily used to encode visual observations. Thus, action information has to be derived purely from robot data, which is expensive to collect! In this work, we present a scalable alternative where the visual representations can help directly infer robot actions. We observe that vision encoders express relationships between image observations as \textit{distances} (e.g. via embedding dot product) that could be used to efficiently plan robot behavior. We operationalize this insight and develop a simple algorithm for acquiring a distance function and dynamics predictor, by fine-tuning a pre-trained representation on human collected video sequences. The final method is able to substantially outperform traditional robot learning baselines (e.g. 70% success v.s. 50% for behavior cloning on pick-place) on a suite of diverse real-world manipulation tasks. It can also generalize to novel objects, without using any robot demonstrations during train time.
@article{wang2023manipulate,
title={Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations},
author={Wang, Jianren and Dasari, Sudeep and Srirama, Mohan Kumar and Tulsiani, Shubham and Gupta, Abhinav},
journal={ICCV},
year={2023}
}
|