
Publications
You can also find my articles on my Google Scholar Profile.Research Topics:Show selected / Show all by date / Show all by topic
Self-supervised Learning / Reinforcement Learning
| Robot Parkour Learning Ziwen Zhuang*, Zipeng Fu*, Jianren Wang*, Christopher Atkeson, Soren Schwertfeger, Chelsea Finn, Hang Zhao 2023 Conference on Robot Learning (Best Systems Paper Finalist) [Project Page] [Code] [Abstract] [Bibtex] Parkour is a grand challenge for legged locomotion that requires robots to overcome various obstacles rapidly in complex environments. Existing methods can generate either diverse but blind locomotion skills or vision-based but specialized skills by using reference animal data or complex rewards. However, autonomous parkour requires robots to learn generalizable skills that are both vision-based and diverse to perceive and react to various scenarios. In this work, we propose a system for learning a single end-to-end vision-based parkour policy of diverse parkour skills using a simple reward without any reference motion data. We develop a reinforcement learning method inspired by direct collocation to generate parkour skills, including climbing over high obstacles, leaping over large gaps, crawling beneath low barriers, squeezing through thin slits, and running. We distill these skills into a single vision-based parkour policy and transfer it to a quadrupedal robot using its egocentric depth camera. We demonstrate that our system can empower two different low-cost robots to autonomously select and execute appropriate parkour skills to traverse challenging real-world environments.
@article{zhuang2023parkour,
title={Robot Parkour Learning},
author={Zhuang, Ziwen and Fu, Zipeng and Wang, Jianren and Atkeson, Christopher and Schwertfeger, Soren and Finn, Chelsea and Zhao, Hang},
journal={CoRL},
year={2023}
}
|
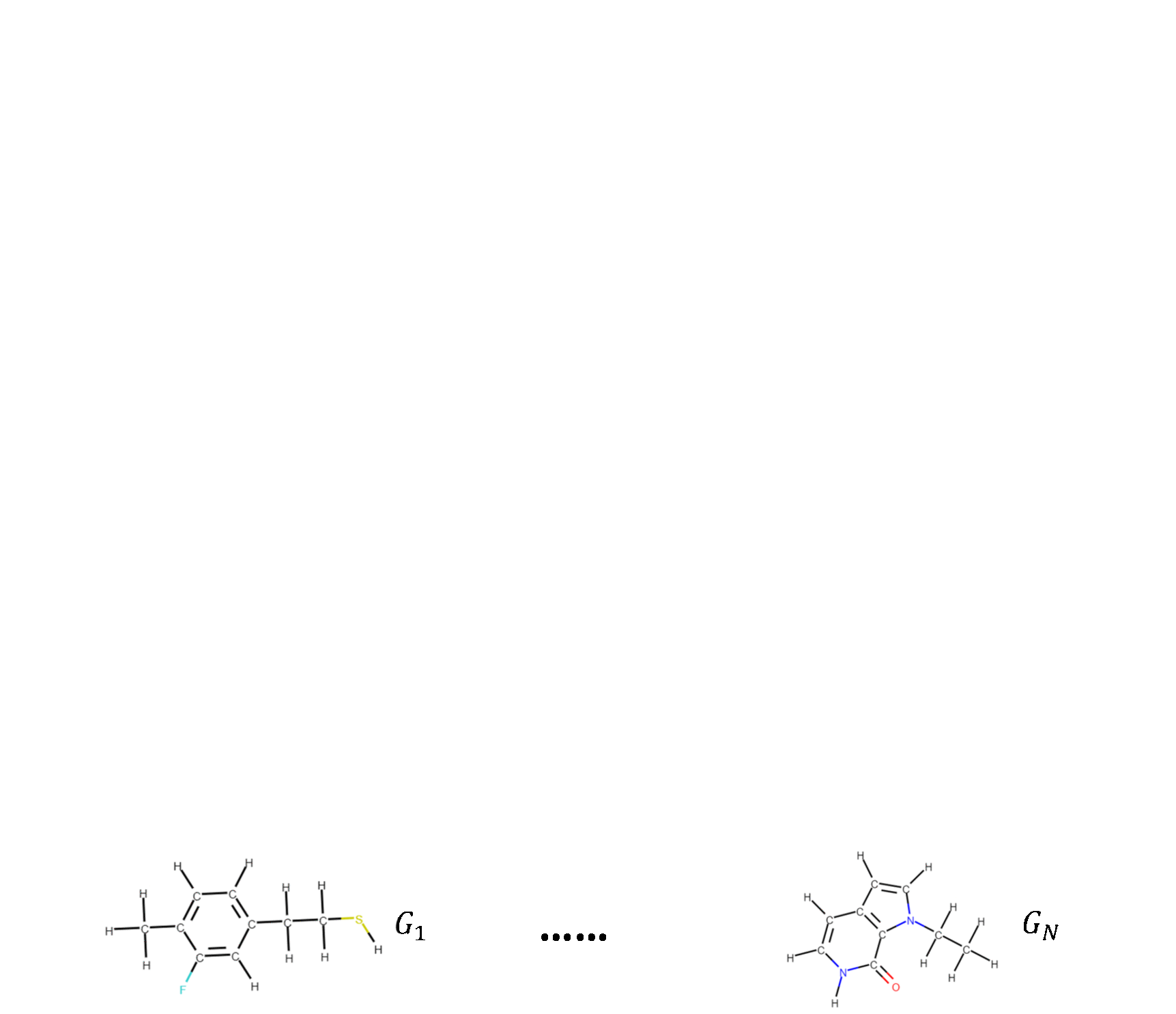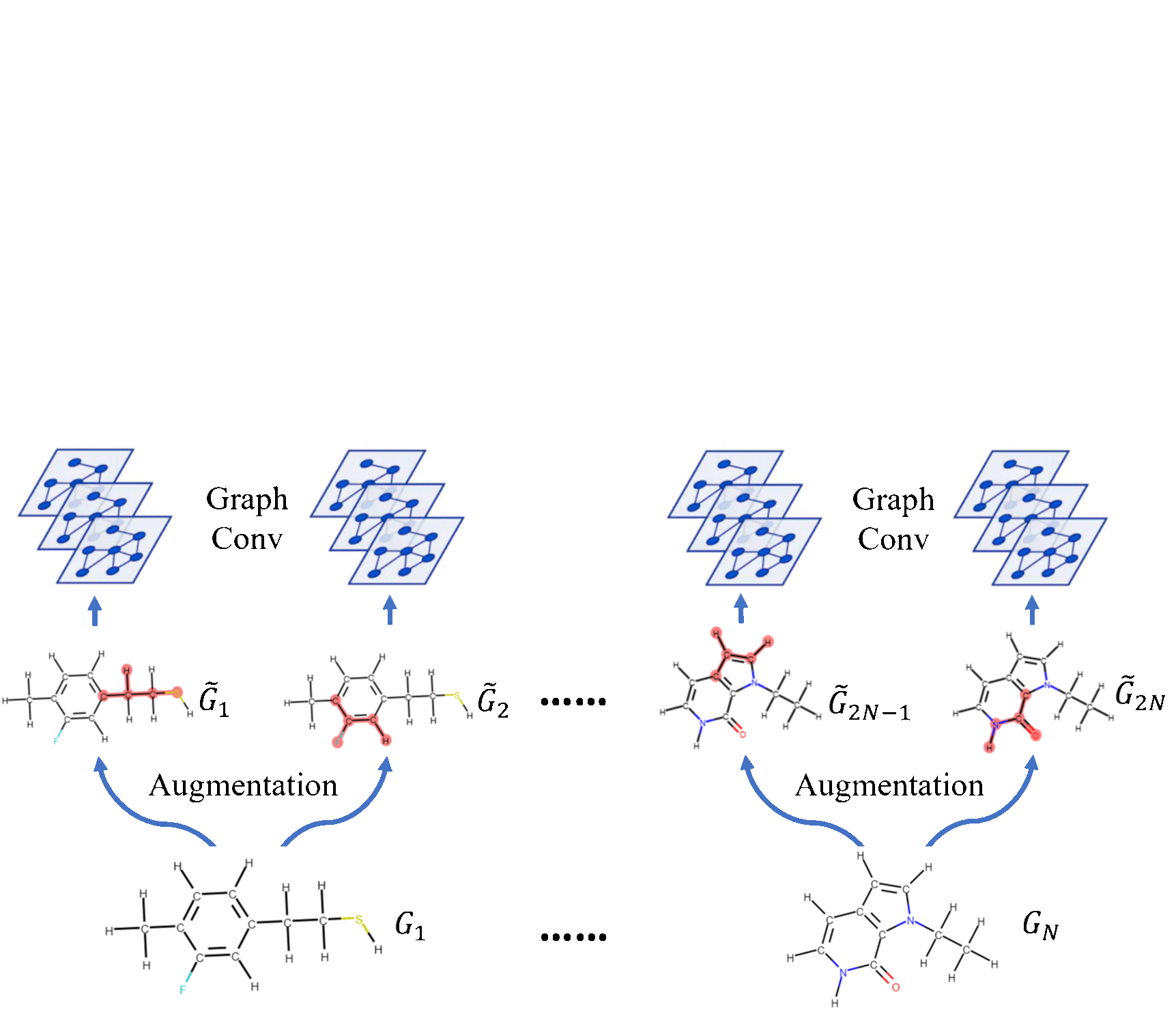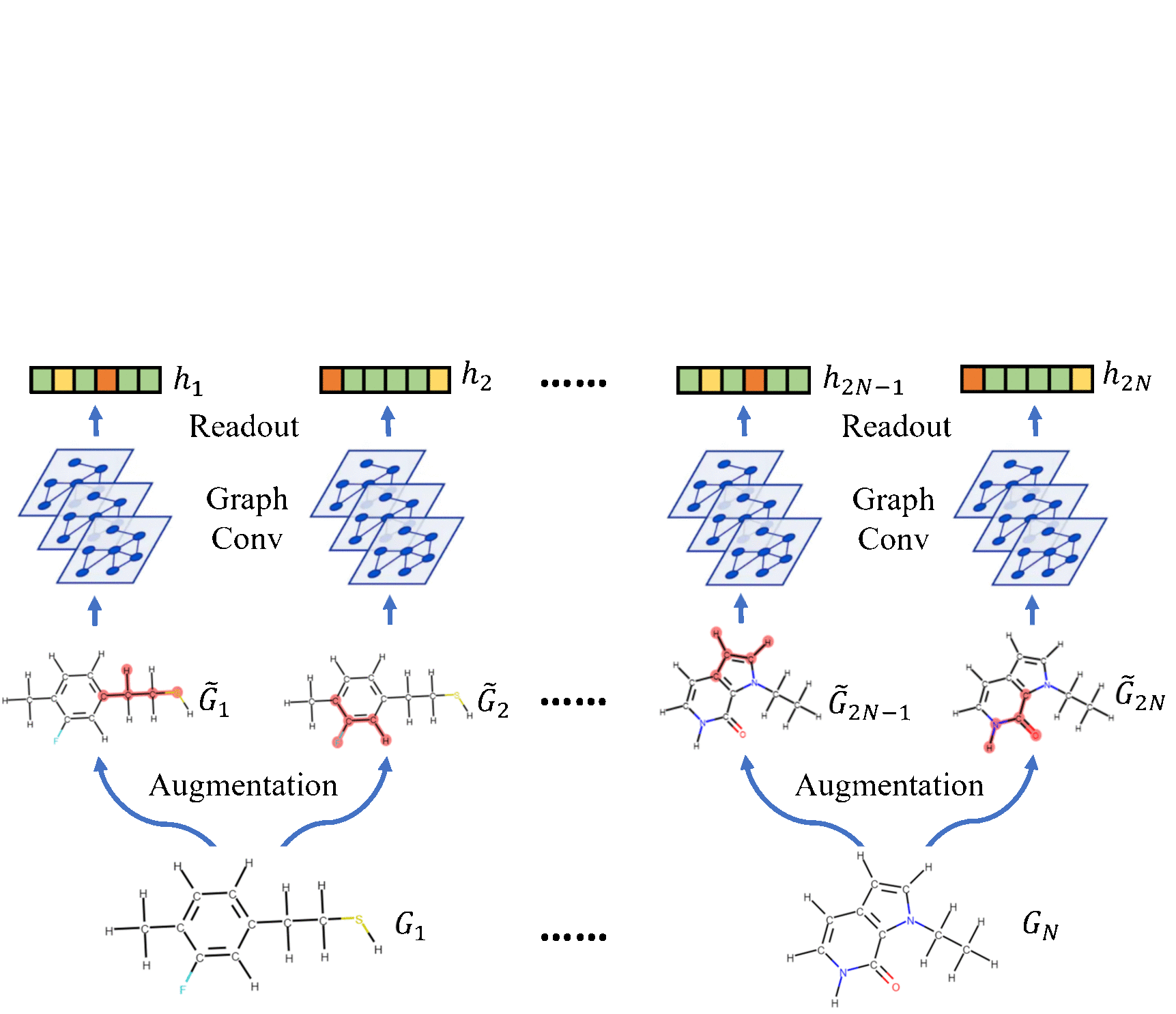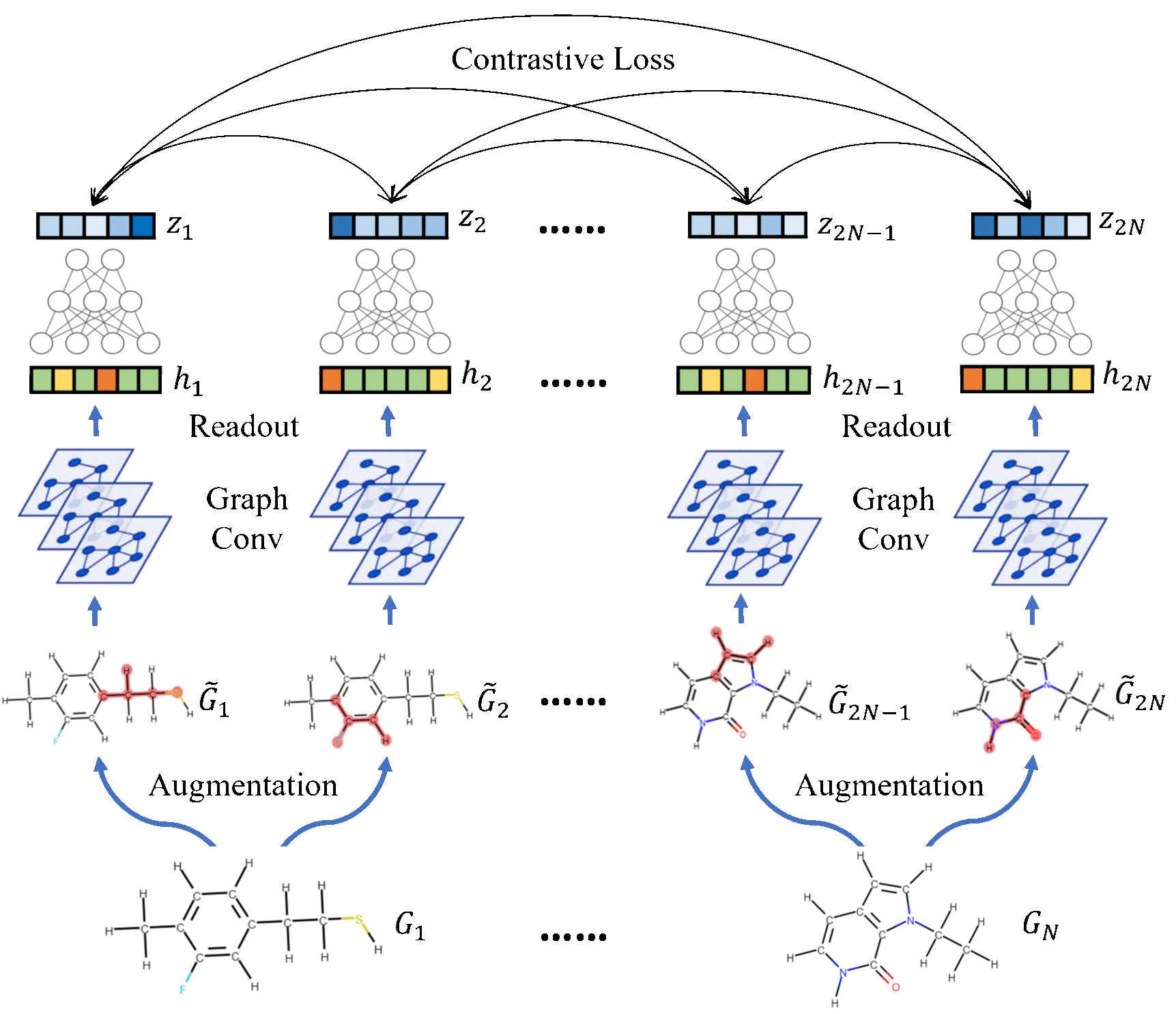 | Molecular Contrastive Learning of Representations via Graph Neural Networks Yuyang Wang, Jianren Wang, Zhonglin Cao, and Amir Barati Farimani Nature Machine Intelligence [Code] [Abstract] [Bibtex] Molecular machine learning bears promise for efficient molecule property prediction and drug discovery. However, due to the limited labeled data and the giant chemical space, machine learning models trained via supervised learning perform poorly in generalization. This greatly limits the applications of machine learning methods for molecular design and discovery. In this work, we present MolCLR: Molecular Contrastive Learning of Representations via Graph Neural Networks (GNNs), a self-supervised learning framework for large unlabeled molecule datasets. Specifically, we first build a molecular graph, where each node represents an atom and each edge represents a chemical bond. A GNN is then used to encode the molecule graph. We propose three novel molecule graph augmentations: atom masking, bond deletion, and subgraph removal. A contrastive estimator is utilized to maximize the agreement of different graph augmentations from the same molecule. Experiments show that molecule representations learned by MolCLR can be transferred to multiple downstream molecular property prediction tasks. Our method thus achieves state-of-the-art performance on many challenging datasets. We also prove the efficiency of our proposed molecule graph augmentations on supervised molecular classification tasks.
@article{wang2021molclr,
title={Molecular Contrastive Learning of Representations via Graph Neural Networks},
author={Wang, Yuyang and Wang, Jianren and Cao, Zhonglin and Farimani, Amir Barati},
journal={Nature Machine Intelligence},
year={2022}
}
|
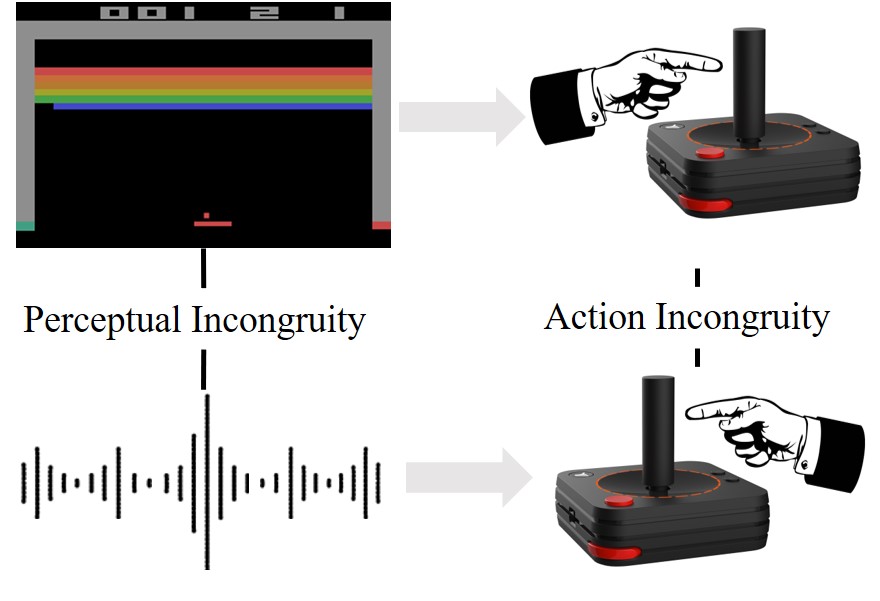 | SEMI: Self-supervised Exploration via Multisensory Incongruity Jianren Wang*, Ziwen Zhuang*, Hang Zhao (* indicates equal contribution) 2022 IEEE International Conference on Robotics and Automation [Project Page] [Code] [Abstract] [Bibtex] Efficient exploration is a long-standing problem in reinforcement learning since extrinsic rewards are usually sparse or missing. A popular solution to this issue is to feed an agent with novelty signals as intrinsic rewards. In this work, we introduce SEMI, a self-supervised exploration policy by incentivizing the agent to maximize a new novelty signal: multisensory incongruity, which can be measured in two aspects, perception incongruity and action incongruity. The former represents the misalignment of the multisensory inputs, while the latter represents the variance of an agent's policies under different sensory inputs. Specifically, an alignment predictor is learned to detect whether multiple sensory inputs are aligned, the error of which is used to measure perception incongruity. A policy model takes different combinations of the multisensory observations as input, and outputs actions for exploration. The variance of actions is further used to measure action incongruity. Using both incongruities as intrinsic rewards, SEMI allows an agent to learn skills by exploring in a self-supervised manner without any external rewards. We further show that SEMI is compatible with extrinsic rewards and it improves sample efficiency of policy learning. The effectiveness of SEMI is demonstrated across a variety of benchmark environments including object manipulation and audio-visual games.
@article{wang2022semi,
title={SEMI: Self-supervised Exploration via Multisensory Incongruity},
author={Wang, Jianren and Zhuang, Ziwen and Zhao, Hang},
journal={IEEE International Conference on Robotics and Automation},
year={2022}
}
|
 | Semi-supervised 3D Object Detection via Temporal Graph Neural Networks Jianren Wang, Haiming Gang, Siddharth Ancha, Yi-ting Chen, David Held 2021 International Conference on 3D Vision [Project Page] [Code] [Abstract] [Bibtex] 3D object detection plays an important role in autonomous driving and other robotics applications. However, these detectors usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging large amounts of unlabeled point cloud videos by semi-supervised learning of 3D object detectors via temporal graph neural networks. Our insight is that temporal smoothing can create more accurate detection results on unlabeled data, and these smoothed detections can then be used to retrain the detector. We learn to perform this temporal reasoning with a graph neural network, where edges represent the relationship between candidate detections in different time frames.
@article{wang2021sodtgnn,
title={Semi-supervised 3D Object Detection via Temporal Graph Neural Networks},
author={Wang, Jianren and Gang, Haiming and Ancha, Siddharth and Chen, Yi-ting and Held, David},
journal={International Conference on 3D Vision},
year={2021}
}
|
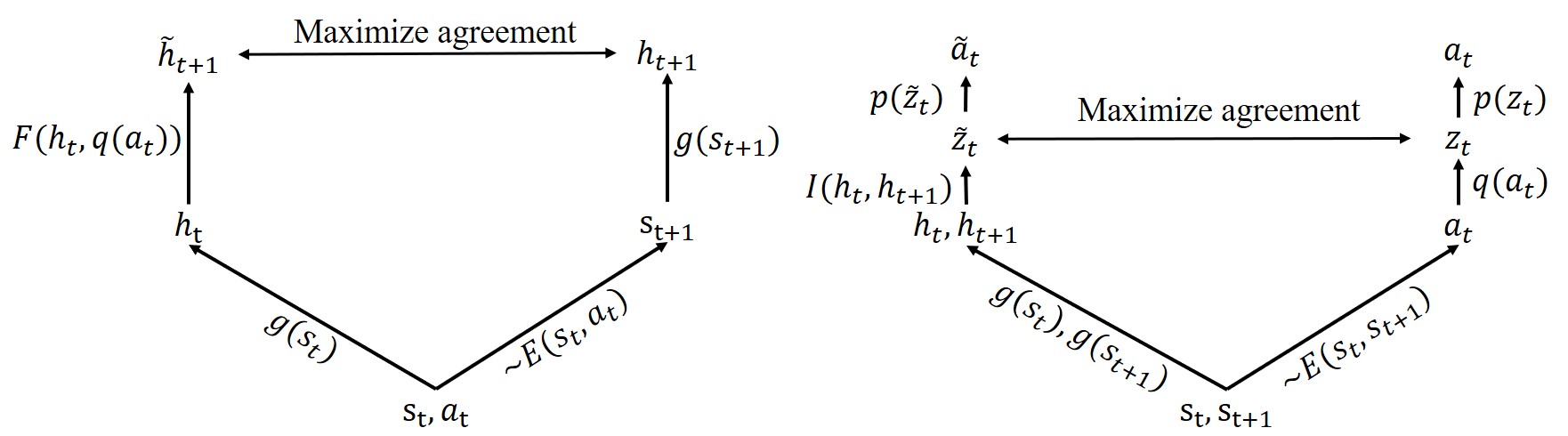 | CLOUD: Contrastive Learning of Unsupervised Dynamics Jianren Wang*, Yujie Lu*, Hang Zhao (* indicates equal contribution) 2020 Conference on Robot Learning [Project Page] [Code] [Abstract] [Bibtex] Developing agents that can perform complex control tasks from high dimensional observations such as pixels is challenging due to difficulties in learning dynamics efficiently. In this work, we propose to learn forward and inverse dynamics in a fully unsupervised manner via contrastive estimation. Specifically, we train a forward dynamics model and an inverse dynamics model in the feature space of states and actions with data collected from random exploration. Unlike most existing deterministic models, our energy-based model takes into account the stochastic nature of agent-environment interactions. We demonstrate the efficacy of our approach across a variety of tasks including goal-directed planning and imitation from observations.
@inproceedings{jianren20cloud,
Author = {Wang, Jianren and Lu, Yujie and Zhao, Hang},
Title = {CLOUD: Contrastive Learning of Unsupervised Dynamics},
Booktitle = {CORL},
Year = {2020}
}
|
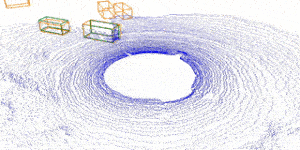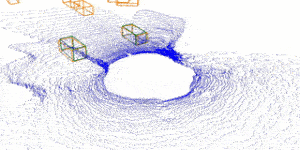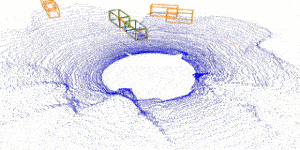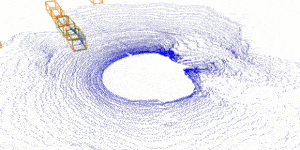 | Inverting the Forecasting Pipeline with SPF2: Sequential Pointcloud Forecasting for Sequential Pose Forecasting Xinshuo Weng, Jianren Wang, Sergey Levine, Kris Kitani, Nick Rhinehart 2020 Conference on Robot Learning [Project Page] [Code] [Abstract] [Bibtex] Many autonomous systems forecast aspects of the future in order to aid decision-making. For example, self-driving vehicles and robotic manipulation systems often forecast future object poses by first detecting and tracking objects. However, this detect-then-forecast pipeline is expensive to scale, as pose forecasting algorithms typically require labeled sequences of object poses, which are costly to obtain in 3D space. Can we scale performance without requiring additional labels? We hypothesize yes, and propose inverting the detect-then-forecast pipeline. Instead of detecting, tracking and then forecasting the objects, we propose to first forecast 3D sensor data (e.g., point clouds with $100$k points) and then detect/track objects on the predicted point cloud sequences to obtain future poses, i.e., a forecast-then-detect pipeline. This inversion makes it less expensive to scale pose forecasting, as the sensor data forecasting task requires no labels. Part of this work's focus is on the challenging first step -- Sequential Pointcloud Forecasting (SPF), for which we also propose an effective approach, SPFNet. To compare our forecast-then-detect pipeline relative to the detect-then-forecast pipeline, we propose an evaluation procedure and two metrics. Through experiments on a robotic manipulation dataset and two driving datasets, we show that SPFNet is effective for the SPF task, our forecast-then-detect pipeline outperforms the detect-then-forecast approaches to which we compared, and that pose forecasting performance improves with the addition of unlabeled data.
@article{Weng2020_SPF2,
author = {Weng, Xinshuo and Wang, Jianren and Levine, Sergey
and Kitani, Kris and Rhinehart, Nick},
journal = {CoRL},
title = {Inverting the Pose Forecasting Pipeline with SPF2:
Sequential Pointcloud Forecasting for Sequential Pose Forecasting},
year = {2020}
}
|
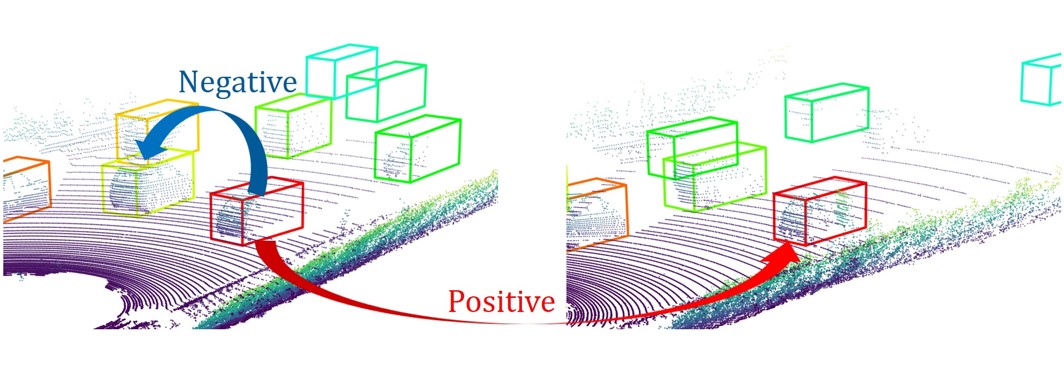 | Uncertainty-aware Self-supervised 3D Data Association Jianren Wang, Siddharth Ancha, Yi-Ting Chen, David Held 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems [Project Page] [Code] [Abstract] [Bibtex] 3D object trackers usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging vast unlabeled datasets by self-supervised metric learning of 3D object trackers, with a focus on data association. Large scale annotations for unlabeled data are cheaply obtained by automatic object detection and association across frames. We show how these self-supervised annotations can be used in a principled manner to learn point-cloud embeddings that are effective for 3D tracking. We estimate and incorporate uncertainty in self-supervised tracking to learn more robust embeddings, without needing any labeled data. We design embeddings to differentiate objects across frames, and learn them using uncertainty-aware self-supervised training. Finally, we demonstrate their ability to perform accurate data association across frames, towards effective and accurate 3D tracking.
@inproceedings{jianren20s3da,
Author = {Wang, Jianren and Ancha, Siddharth and Chen, Yi-Ting and Held, David},
Title = {Uncertainty-aware Self-supervised 3D Data Association},
Booktitle = {IROS},
Year = {2020}
}
|
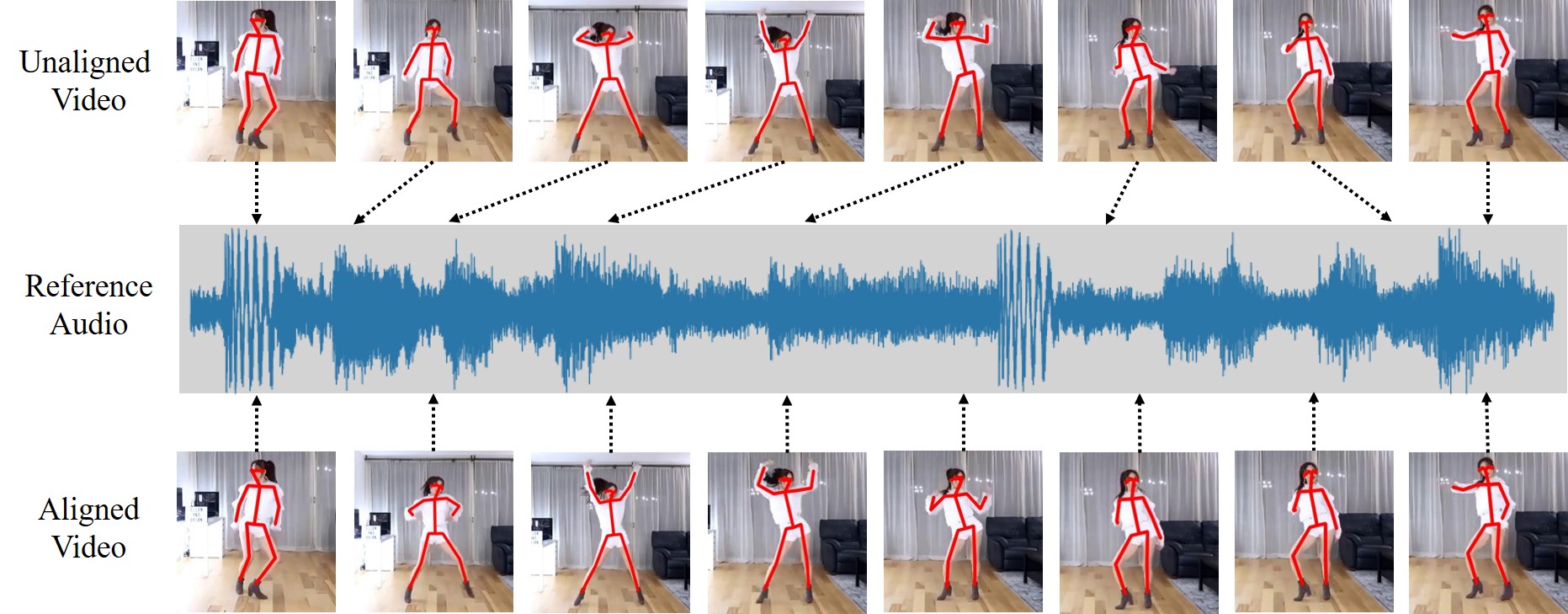 | AlignNet: A Unifying Approach to Audio-Visual Alignment Jianren Wang*, Zhaoyuan Fang*, Hang Zhao (* indicates equal contribution) 2020 Winter Conference on Applications of Computer Vision [Project Page] [Code] [Data] [Abstract] [Bibtex] We present AlignNet, a model designed to synchronize a video with a reference audio under non-uniform and irregular misalignment. AlignNet learns the end-to-end dense correspondence between each frame of a video and an audio. Our method is designed according to simple and well-established principles: attention, pyramidal processing, warping, and affinity function. Together with the model, we release a dancing dataset Dance50 for training and evaluation. Qualitative, quantitative and subjective evaluation results on dance-music alignment and speech-lip alignment demonstrate that our method far outperforms the state-of-the-art methods.
@inproceedings{jianren20alignnet,
Author = {Wang, Jianren and Fang, Zhaoyuan
and Zhao, Hang},
Title = {AlignNet: A Unifying Approach to Audio-Visual Alignment},
Booktitle = {WACV},
Year = {2020}
}
|