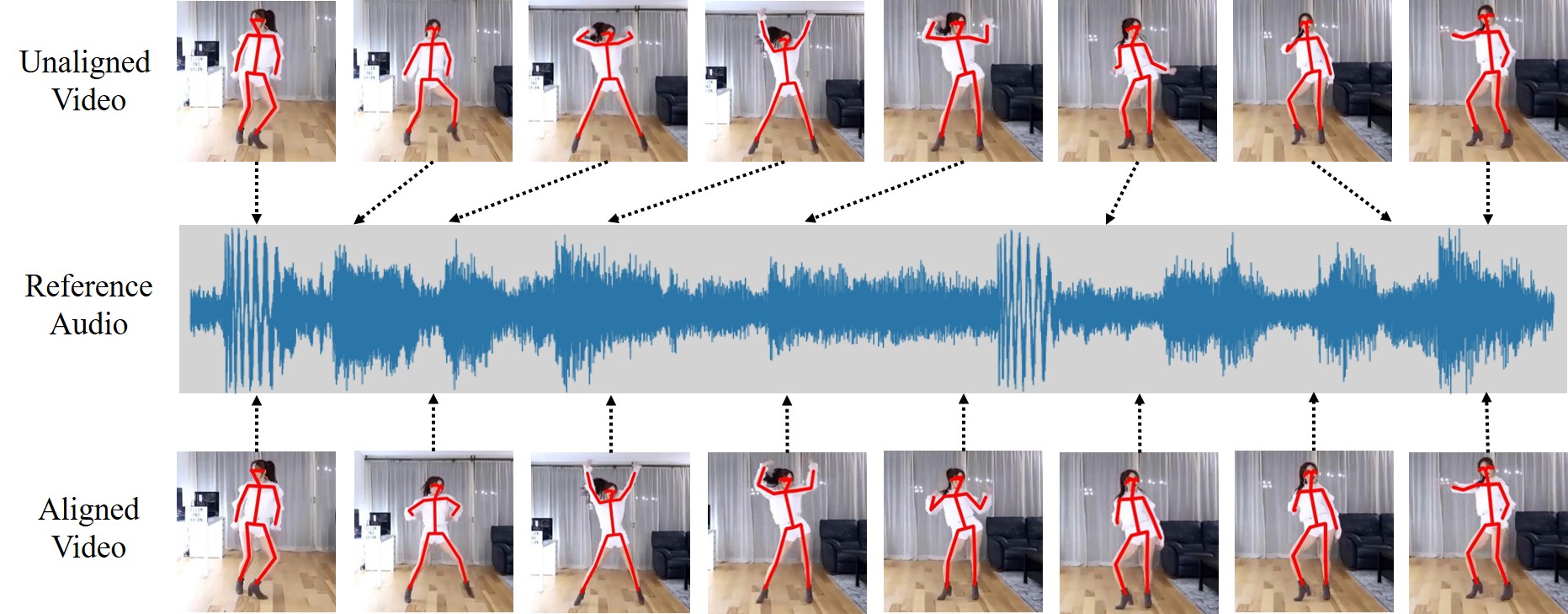
|
|
|
|
|
|
|
|
|
|
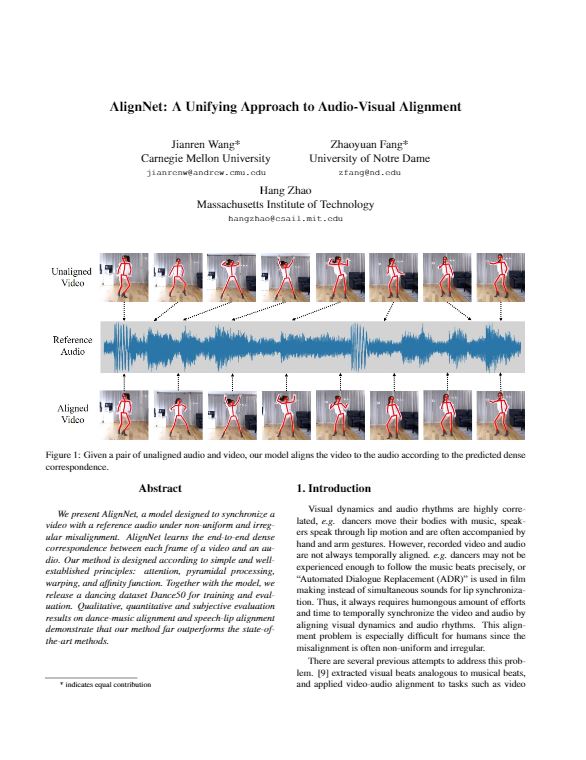
|
Citation |
|
@inproceedings{jianren20alignnet,
Author = {Wang, Jianren and Fang, Zhaoyuan
and Zhao, Hang},
Title = {AlignNet: A Unifying Approach to Audio-Visual Alignment},
Booktitle = {WACV},
Year = {2020}
}
|
Acknowledgements |